# GA snippets for January–March
monthlist <- c("01","02","03")
# Base directory for GA snippet files
base_dir <- "../data/output/ma-snippets"
# Readers (quiet & typed) -----------------------------------------------
read_contract <- function(path) {
read_csv(
path,
skip = 0, # snippets no longer have the original header row
col_types = cols(
contractid = col_character(),
planid = col_double(),
org_type = col_character(),
plan_type = col_character(),
partd = col_character(),
snp = col_character(),
eghp = col_character(),
org_name = col_character(),
org_marketing_name = col_character(),
plan_name = col_character(),
parent_org = col_character(),
contract_date = col_character()
),
show_col_types = FALSE,
progress = FALSE
)
}
read_enroll <- function(path) {
read_csv(
path,
skip = 0,
col_types = cols(
contractid = col_character(),
planid = col_double(),
ssa = col_double(),
fips = col_double(),
state = col_character(),
county = col_character(),
enrollment = col_double()
),
na = "*",
show_col_types = FALSE,
progress = FALSE
)
}
# One-month loader (GA snippets) ----------------------------------------
load_month_ga <- function(m, y) {
c_path <- file.path(base_dir, paste0("ga-contract-", y, "-", m, ".csv"))
e_path <- file.path(base_dir, paste0("ga-enrollment-", y, "-", m, ".csv"))
contract.info <- read_contract(c_path) %>%
distinct(contractid, planid, .keep_all = TRUE)
enroll.info <- read_enroll(e_path)
contract.info %>%
left_join(enroll.info, by = c("contractid", "planid")) %>%
mutate(
month = as.integer(m),
year = y
)
}
# Read all months for a given year, then tidy once ----------------------
y <- 2022 # start with 2022; repeat for 2023 in the notebook
ga_plan_year <- map_dfr(
monthlist,
~ load_month_ga(.x, y)
)Medicare Advantage Data
Ian McCarthy | Emory University
Outline for Today
Recall the Medicare Advantage repository, Medicare Advantage GitHub repository
- Understand data and code structure
- Import files using purrr (in R), or just pandas in python
- Manage (merge and clean) data
- Create new variables
MA Repository
Data structure
Let’s first look through the raw data on our class OneDrive folder:
- Enrollment and contract files
- Service area files
- Plan characteristics
- Penetration files
Code structure
Now let’s turn to the code structure:
- Everything called from main code file. Easy to follow and replicate
- Code separated into key datasets (enrollment (plan) data, service area, landscape, penetration, etc.)
- Some code files are very repetitive because of small changes in naming conventions or how data are arranged over time
Importing Data
Monthly enrollment and contract info
- We follow the same structure as the full
plan_datacode:- Define a list of months.
- Write typed readers for contract and enrollment.
- Write a one-month loader that merges contract + enrollment.
- Use
map_dfr()to stack months into a monthly panel.
- Define a list of months.
import pandas as pd
import os
monthlist = [f"{m:02d}" for m in range(1, 4)]
base_dir = "data/output/ma-snippets"
# Readers ---------------------------------------------------------------
def read_contract(path):
df = pd.read_csv(path)
# Columns mirror the R version: contractid, planid, org_type, plan_type, ...
return df
def read_enroll(path):
df = pd.read_csv(path)
# Columns mirror the R version: contractid, planid, ssa, fips, state, county, enrollment
return df
# One-month loader (GA snippets) ---------------------------------------
def load_month_ga(m, year):
c_path = os.path.join(base_dir, f"ga-contract-{year}-{m}.csv")
e_path = os.path.join(base_dir, f"ga-enrollment-{year}-{m}.csv")
contract_info = read_contract(c_path).drop_duplicates(subset=["contractid", "planid"])
enroll_info = read_enroll(e_path)
merged = contract_info.merge(
enroll_info,
on=["contractid", "planid"],
how="left"
)
merged["month"] = int(m)
merged["year"] = int(year)
return merged
# Read all months for a given year, then stack -------------------------
y = 2022 # start with 2022; repeat for 2023 in the notebook
ga_plan_year = pd.concat(
[load_month_ga(m, y) for m in monthlist],
ignore_index=True
)Rows: 22,182
Columns: 19
$ contractid <chr> "H0111", "H0111", "H0111", "H0111", "H0111", "H0111…
$ planid <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ org_type <chr> "Local CCP", "Local CCP", "Local CCP", "Local CCP",…
$ plan_type <chr> "Local PPO", "Local PPO", "Local PPO", "Local PPO",…
$ partd <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Y…
$ snp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No…
$ eghp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No…
$ org_name <chr> "WELLCARE OF GEORGIA, INC.", "WELLCARE OF GEORGIA, …
$ org_marketing_name <chr> "Wellcare", "Wellcare", "Wellcare", "Wellcare", "We…
$ plan_name <chr> "Wellcare No Premium Open (PPO)", "Wellcare No Prem…
$ parent_org <chr> "Centene Corporation", "Centene Corporation", "Cent…
$ contract_date <chr> "01/01/2018", "01/01/2018", "01/01/2018", "01/01/20…
$ ssa <dbl> 11000, 11030, 11050, 11060, 11070, 11080, 11090, 11…
$ fips <dbl> 13001, 13009, 13013, 13015, 13017, 13019, 13021, 13…
$ state <chr> "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA…
$ county <chr> "Appling", "Baldwin", "Barrow", "Bartow", "Ben Hill…
$ enrollment <dbl> 11, 27, 47, 43, 14, 13, 116, 21, 40, 73, 44, 42, 11…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 202…Collapse to the year level
- Now mimic the
final.plansstep from the full repo:- Tidy the monthly panel (sort + fill IDs and plan/org characteristics).
- Collapse to one row per contract–plan–county–year with summary enrollment stats.
- Tidy the monthly panel (sort + fill IDs and plan/org characteristics).
# Starting point: ga_plan_year (monthly GA plan data for a single year)
ga_plan_year_tidy <- ga_plan_year %>%
arrange(contractid, planid, state, county, month) %>%
group_by(state, county) %>%
fill(fips, .direction = "downup") %>%
ungroup() %>%
group_by(contractid, planid) %>%
fill(plan_type, partd, snp, eghp, plan_name, .direction = "downup") %>%
ungroup() %>%
group_by(contractid) %>%
fill(org_type, org_name, org_marketing_name, parent_org, .direction = "downup") %>%
ungroup()
ga_plans_year <- ga_plan_year_tidy %>%
group_by(contractid, planid, fips, year) %>%
arrange(month, .by_group = TRUE) %>%
summarize(
n_nonmiss = sum(!is.na(enrollment)),
avg_enrollment = ifelse(n_nonmiss > 0, mean(enrollment, na.rm = TRUE), NA_real_),
sd_enrollment = ifelse(n_nonmiss > 1, sd(enrollment, na.rm = TRUE), NA_real_),
min_enrollment = ifelse(n_nonmiss > 0, min(enrollment, na.rm = TRUE), NA_real_),
max_enrollment = ifelse(n_nonmiss > 0, max(enrollment, na.rm = TRUE), NA_real_),
first_enrollment = ifelse(n_nonmiss > 0, first(na.omit(enrollment)), NA_real_),
last_enrollment = ifelse(n_nonmiss > 0, last(na.omit(enrollment)), NA_real_),
state = last(state),
county = last(county),
org_type = last(org_type),
plan_type = last(plan_type),
partd = last(partd),
snp = last(snp),
eghp = last(eghp),
org_name = last(org_name),
org_marketing_name = last(org_marketing_name),
plan_name = last(plan_name),
parent_org = last(parent_org),
contract_date = last(contract_date),
year = last(year),
.groups = "drop"
)# Starting point: ga_plan_year (monthly GA plan data for a single year)
import numpy as np
# Sort and forward-fill IDs and characteristics ------------------------
ga_plan_year_sorted = (
ga_plan_year
.sort_values(["state", "county", "contractid", "planid", "month"])
.copy()
)
# Fill fips within county
ga_plan_year_sorted["fips"] = (
ga_plan_year_sorted
.groupby(["state", "county"])["fips"]
.ffill()
.bfill()
)
# Fill plan-level variables within contract–plan
for col in ["plan_type", "partd", "snp", "eghp", "plan_name"]:
ga_plan_year_sorted[col] = (
ga_plan_year_sorted
.groupby(["contractid", "planid"])[col]
.ffill()
.bfill()
)
# Fill org-level variables within contract
for col in ["org_type", "org_name", "org_marketing_name", "parent_org"]:
ga_plan_year_sorted[col] = (
ga_plan_year_sorted
.groupby("contractid")[col]
.ffill()
.bfill()
)
# Helpers to get first/last non-missing enrollment ---------------------
def first_nonmissing(x):
x = x.dropna()
return x.iloc[0] if not x.empty else np.nan
def last_nonmissing(x):
x = x.dropna()
return x.iloc[-1] if not x.empty else np.nan
# Collapse to yearly panel ---------------------------------------------
ga_plans_year = (
ga_plan_year_sorted
.sort_values(["contractid", "planid", "fips", "year", "month"])
.groupby(["contractid", "planid", "fips", "year"], as_index=False)
.agg(
n_nonmiss = ("enrollment", lambda x: x.notna().sum()),
avg_enrollment = ("enrollment", "mean"),
sd_enrollment = ("enrollment", "std"),
min_enrollment = ("enrollment", "min"),
max_enrollment = ("enrollment", "max"),
first_enrollment = ("enrollment", first_nonmissing),
last_enrollment = ("enrollment", last_nonmissing),
state = ("state", "last"),
county = ("county", "last"),
org_type = ("org_type", "last"),
plan_type = ("plan_type", "last"),
partd = ("partd", "last"),
snp = ("snp", "last"),
eghp = ("eghp", "last"),
org_name = ("org_name", "last"),
org_marketing_name = ("org_marketing_name", "last"),
plan_name = ("plan_name", "last"),
parent_org = ("parent_org", "last"),
contract_date = ("contract_date", "last"),
year_out = ("year", "last"),
)
.rename(columns={"year_out": "year"})
)Rows: 7,612
Columns: 23
$ contractid <chr> "H0111", "H0111", "H0111", "H0111", "H0111", "H0111…
$ planid <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ fips <dbl> 13001, 13009, 13013, 13015, 13017, 13019, 13021, 13…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 202…
$ n_nonmiss <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 3, 3, …
$ avg_enrollment <dbl> 11.66667, 27.00000, 46.33333, 47.33333, 14.33333, 1…
$ sd_enrollment <dbl> 0.5773503, 1.0000000, 0.5773503, 5.1316014, 0.57735…
$ min_enrollment <dbl> 11, 26, 46, 43, 14, 13, 116, 21, 40, 69, 43, 42, 11…
$ max_enrollment <dbl> 12, 28, 47, 53, 15, 17, 118, 23, 45, 73, 45, 45, 11…
$ first_enrollment <dbl> 11, 27, 47, 43, 14, 13, 116, 21, 40, 73, 44, 42, 11…
$ last_enrollment <dbl> 12, 26, 46, 53, 14, 16, 117, 23, 44, 69, 43, 44, 11…
$ state <chr> "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA…
$ county <chr> "Appling", "Baldwin", "Barrow", "Bartow", "Ben Hill…
$ org_type <chr> "Local CCP", "Local CCP", "Local CCP", "Local CCP",…
$ plan_type <chr> "Local PPO", "Local PPO", "Local PPO", "Local PPO",…
$ partd <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Y…
$ snp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No…
$ eghp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No…
$ org_name <chr> "WELLCARE OF GEORGIA, INC.", "WELLCARE OF GEORGIA, …
$ org_marketing_name <chr> "Wellcare", "Wellcare", "Wellcare", "Wellcare", "We…
$ plan_name <chr> "Wellcare No Premium Open (PPO)", "Wellcare No Prem…
$ parent_org <chr> "Centene Corporation", "Centene Corporation", "Cent…
$ contract_date <chr> "01/01/2018", "01/01/2018", "01/01/2018", "01/01/20…Import and collapse service area data
- Follow the same pattern as the full
service-areacode:- Define a list of months.
- Write a typed reader for service area.
- Write a one-month loader.
- Use
map_dfr()to stack months and then collapse to a yearly panel.
- Define a list of months.
- Work directly with the GA service-area snippets (
ga-service-area-YYYY-MM.csv).
# GA snippets for January–March
monthlist <- sprintf("%02d", 1:3)
base_dir_sa <- "../data/output/ma-snippets"
# Reader for GA service-area snippets -----------------------------------
read_service_area_ga <- function(path) {
read_csv(
path,
skip = 0, # snippets already have clean headers
col_types = cols(
contractid = col_character(),
org_name = col_character(),
org_type = col_character(),
plan_type = col_character(),
partial = col_logical(),
eghp = col_character(),
ssa = col_double(),
fips = col_double(),
county = col_character(),
state = col_character()
),
na = "*",
show_col_types = FALSE,
progress = FALSE
)
}
# One-month loader (GA service area) -----------------------------------
load_month_sa_ga <- function(m, y) {
path <- file.path(base_dir_sa, paste0("ga-service-area-", y, "-", m, ".csv"))
read_service_area_ga(path) %>%
mutate(
month = as.integer(m),
year = y
)
}
# Read all months for a given year, then tidy once ---------------------
y <- 2022 # start with 2022; repeat for 2023 in the notebook
service_year_ga <- map_dfr(
monthlist,
~ load_month_sa_ga(.x, y)
)
# Ensure stable order before fills
service_year_ga <- service_year_ga %>%
arrange(contractid, fips, state, county, month)
# Fill missing identifiers / labels
service_year_ga <- service_year_ga %>%
group_by(state, county) %>%
fill(fips, .direction = "downup") %>%
ungroup() %>%
group_by(contractid) %>%
fill(plan_type, partial, eghp, org_type, org_name, .direction = "downup") %>%
ungroup()
# Collapse to yearly: one row per contract √ó county (fips) √ó year ------
ga_service_year <- service_year_ga %>%
group_by(contractid, fips, year) %>%
arrange(month, .by_group = TRUE) %>%
summarize(
state = last(state),
county = last(county),
org_name = last(org_name),
org_type = last(org_type),
plan_type = last(plan_type),
partial = last(partial),
eghp = last(eghp),
ssa = last(ssa),
.groups = "drop"
)import pandas as pd
import numpy as np
import os
monthlist = [f"{m:02d}" for m in range(1, 4)]
base_dir_sa = "data/output/ma-snippets"
# Reader for GA service-area snippets ----------------------------------
def read_service_area_ga(path):
df = pd.read_csv(path)
# Expected columns:
# contractid, org_name, org_type, plan_type, partial, eghp,
# ssa, fips, county, state
return df
# One-month loader (GA service area) -----------------------------------
def load_month_sa_ga(m, year):
path = os.path.join(base_dir_sa, f"ga-service-area-{year}-{m}.csv")
df = read_service_area_ga(path)
df["month"] = int(m)
df["year"] = int(year)
return df
# Read all months for a given year, then stack -------------------------
y = 2022 # start with 2022; repeat for 2023 in the notebook
service_year_ga = pd.concat(
[load_month_sa_ga(m, y) for m in monthlist],
ignore_index=True
)
# Ensure stable order before fills
service_year_ga = service_year_ga.sort_values(
["contractid", "fips", "state", "county", "month"]
)
# Fill missing identifiers / labels ------------------------------------
# Fill fips within state–county
service_year_ga["fips"] = (
service_year_ga
.groupby(["state", "county"])["fips"]
.ffill()
.bfill()
)
# Fill contract-level info within contractid
for col in ["plan_type", "partial", "eghp", "org_type", "org_name"]:
service_year_ga[col] = (
service_year_ga
.groupby("contractid")[col]
.ffill()
.bfill()
)
# Collapse to yearly: one row per contract √ó county (fips) √ó year ------
ga_service_year = (
service_year_ga
.sort_values(["contractid", "fips", "year", "month"])
.groupby(["contractid", "fips", "year"], as_index=False)
.agg(
state = ("state", "last"),
county = ("county", "last"),
org_name = ("org_name", "last"),
org_type = ("org_type", "last"),
plan_type = ("plan_type", "last"),
partial = ("partial", "last"),
eghp = ("eghp", "last"),
ssa = ("ssa", "last"),
)
)Rows: 12,028
Columns: 13
$ contractid <chr> "H0111", "H0111", "H0111", "H0111", "H0111", "H0111", "H011…
$ org_name <chr> "WELLCARE OF GEORGIA, INC.", "WELLCARE OF GEORGIA, INC.", "…
$ org_type <chr> "Local CCP", "Local CCP", "Local CCP", "Local CCP", "Local …
$ plan_type <chr> "Local PPO", "Local PPO", "Local PPO", "Local PPO", "Local …
$ partial <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ eghp <chr> "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",…
$ ssa <dbl> 11000, 11000, 11000, 11010, 11010, 11010, 11011, 11011, 110…
$ fips <dbl> 13001, 13001, 13001, 13003, 13003, 13003, 13005, 13005, 130…
$ county <chr> "Appling", "Appling", "Appling", "Atkinson", "Atkinson", "A…
$ state <chr> "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA",…
$ notes <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ month <int> 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2,…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022,…Rows: 4,011
Columns: 11
$ contractid <chr> "H0111", "H0111", "H0111", "H0111", "H0111", "H0111", "H011…
$ fips <dbl> 13001, 13003, 13005, 13007, 13009, 13011, 13013, 13015, 130…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022,…
$ state <chr> "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA",…
$ county <chr> "Appling", "Atkinson", "Bacon", "Baker", "Baldwin", "Banks"…
$ org_name <chr> "WELLCARE OF GEORGIA, INC.", "WELLCARE OF GEORGIA, INC.", "…
$ org_type <chr> "Local CCP", "Local CCP", "Local CCP", "Local CCP", "Local …
$ plan_type <chr> "Local PPO", "Local PPO", "Local PPO", "Local PPO", "Local …
$ partial <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ eghp <chr> "", "", "", "", "", "", "", "", "", "", "", "", "", "", "",…
$ ssa <dbl> 11000, 11010, 11011, 11020, 11030, 11040, 11050, 11060, 110…Characteristics and penetration files
- In the full repo,
3_plan-characteristics-YYYY.Rand4_penetration.Rbuild yearly plan-characteristics (final.landscape) and penetration (final.penetration) files. - Here we start from the corresponding GA snippets that were already created from those yearly files:
ga-landscape-2022.csvga-penetration-2022.csv
y <- 2022
base_dir <- "../data/output/ma-snippets"
# GA plan characteristics (landscape) -----------------------------------
ga_landscape <- read_csv(
file.path(base_dir, paste0("ga-landscape-", y, ".csv")),
show_col_types = FALSE
)
# GA penetration data ---------------------------------------------------
ga_penetration <- read_csv(
file.path(base_dir, paste0("ga-penetration-", y, ".csv")),
show_col_types = FALSE
)
# These are already yearly GA files, analogous to final.landscape and final.penetration
# in the full Medicare-Advantage repo.import pandas as pd
import os
y = 2022
base_dir = "data/output/ma-snippets"
# GA plan characteristics (landscape) ----------------------------------
ga_landscape = pd.read_csv(
os.path.join(base_dir, f"ga-landscape-{y}.csv")
)
# GA penetration data --------------------------------------------------
ga_penetration = pd.read_csv(
os.path.join(base_dir, f"ga-penetration-{y}.csv")
)
# These are already yearly GA files, analogous to the R objects
# final.landscape and final.penetration in the full repo.Rows: 7,718
Columns: 7
$ contractid <chr> "H0111", "H0111", "H0111", "H0111", "H1112", "H1112", "H…
$ planid <dbl> 1, 2, 3, 5, 34, 39, 42, 43, 1, 4, 25, 34, 38, 46, 47, 15…
$ premium <dbl> 0.0, 55.0, 85.0, 0.0, 0.0, 0.0, 0.0, 32.4, NA, NA, 0.0, …
$ premium_partc <dbl> 0.0, 31.9, 63.7, 0.0, NA, 0.0, 0.0, 0.0, NA, NA, 0.0, NA…
$ premium_partd <dbl> 0.0, 23.1, 21.3, 0.0, NA, 0.0, 0.0, 32.4, NA, NA, 0.0, N…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 20…
$ county <chr> "Appling", "Appling", "Appling", "Appling", "Appling", "…Rows: 159
Columns: 6
$ fips <dbl> 13001, 13003, 13005, 13007, 13009, 13011, 13013, 13015, …
$ county <chr> "Appling", "Atkinson", "Bacon", "Baker", "Baldwin", "Ban…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 20…
$ avg_eligibles <dbl> 3963.4167, 1370.3333, 2209.8333, 755.0833, 9245.8333, 39…
$ avg_enrolled <dbl> 2190.0000, 798.5833, 1090.7500, 463.8333, 5504.9167, 203…
$ ssa <dbl> 11000, 11010, 11011, 11020, 11030, 11040, 11050, 11060, …Managing the data
Merging everything together
- Now mirror the
final.maconstruction from the full repo, but focusing on GA and 2022 only. - Starting objects (all for 2022):
ga_plans_year– yearly GA plan panel (from contracts + enrollment).
ga_service_year– yearly GA service-area panel.
ga_landscape– GA plan characteristics (landscape, incl.premium_partc).
ga_penetration– GA penetration data.
# 1. Merge plans and service areas (contract √ó fips √ó year) --------------
ga_ma_2022 <- ga_plans_year %>%
inner_join(
ga_service_year %>%
select(contractid, fips, year),
by = c("contractid", "fips", "year")
) %>%
# 2. Apply basic filters, similar to full repo
filter(
state == "GA",
snp == "No",
(planid < 800 | planid >= 900),
!is.na(planid),
!is.na(fips)
)
# 3. Merge penetration data (by county FIPS and year) -------------------
ga_ma_2022 <- ga_ma_2022 %>%
left_join(
ga_penetration %>% select(-county),
by = c("fips", "year")
)
# 4. Merge plan characteristics / premiums (landscape) ------------------
ga_ma_2022 <- ga_ma_2022 %>%
left_join(
ga_landscape,
by = c("contractid", "planid", "county", "year")
)
# ga_ma_2022 is now a GA plan–county–year dataset with enrollment,
# service area, penetration, and premium_partc information for 2022.# 1. Merge plans and service areas (contract √ó fips √ó year) --------------
ga_ma_2022 = (
ga_plans_year
.merge(
ga_service_year[["contractid", "fips", "state", "county", "year"]],
on=["contractid", "fips", "year"],
how="inner"
)
)
# 2. Apply basic filters, similar to full repo ---------------------------
ga_ma_2022 = ga_ma_2022[
(ga_ma_2022["state"] == "GA")
& (ga_ma_2022["snp"] == "No")
& ((ga_ma_2022["planid"] < 800) | (ga_ma_2022["planid"] >= 900))
& ga_ma_2022["planid"].notna()
& ga_ma_2022["fips"].notna()
].copy()
# 3. Merge penetration data (by county FIPS and year) -------------------
ga_ma_2022 = ga_ma_2022.merge(
ga_penetration,
on=["fips", "year"],
how="left"
)
# 4. Merge plan characteristics / premiums (landscape) ------------------
ga_ma_2022 = ga_ma_2022.merge(
ga_landscape,
on=["contractid", "planid", "county", "year"],
how="left"
)
# ga_ma_2022 is now a GA plan–county–year dataset with enrollment,
# service area, penetration, and premium_partc information for 2022.Rows: 3,096
Columns: 29
$ contractid <chr> "H0111", "H0111", "H0111", "H0111", "H0111", "H0111…
$ planid <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ fips <dbl> 13001, 13009, 13013, 13015, 13017, 13019, 13021, 13…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 202…
$ n_nonmiss <int> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 2, 3, 3, …
$ avg_enrollment <dbl> 11.66667, 27.00000, 46.33333, 47.33333, 14.33333, 1…
$ sd_enrollment <dbl> 0.5773503, 1.0000000, 0.5773503, 5.1316014, 0.57735…
$ min_enrollment <dbl> 11, 26, 46, 43, 14, 13, 116, 21, 40, 69, 43, 42, 11…
$ max_enrollment <dbl> 12, 28, 47, 53, 15, 17, 118, 23, 45, 73, 45, 45, 11…
$ first_enrollment <dbl> 11, 27, 47, 43, 14, 13, 116, 21, 40, 73, 44, 42, 11…
$ last_enrollment <dbl> 12, 26, 46, 53, 14, 16, 117, 23, 44, 69, 43, 44, 11…
$ state <chr> "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA", "GA…
$ county <chr> "Appling", "Baldwin", "Barrow", "Bartow", "Ben Hill…
$ org_type <chr> "Local CCP", "Local CCP", "Local CCP", "Local CCP",…
$ plan_type <chr> "Local PPO", "Local PPO", "Local PPO", "Local PPO",…
$ partd <chr> "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Yes", "Y…
$ snp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No…
$ eghp <chr> "No", "No", "No", "No", "No", "No", "No", "No", "No…
$ org_name <chr> "WELLCARE OF GEORGIA, INC.", "WELLCARE OF GEORGIA, …
$ org_marketing_name <chr> "Wellcare", "Wellcare", "Wellcare", "Wellcare", "We…
$ plan_name <chr> "Wellcare No Premium Open (PPO)", "Wellcare No Prem…
$ parent_org <chr> "Centene Corporation", "Centene Corporation", "Cent…
$ contract_date <chr> "01/01/2018", "01/01/2018", "01/01/2018", "01/01/20…
$ avg_eligibles <dbl> 3963.417, 9245.833, 13986.417, 19792.083, 3749.583,…
$ avg_enrolled <dbl> 2190.000, 5504.917, 7437.583, 10180.667, 2202.667, …
$ ssa <dbl> 11000, 11030, 11050, 11060, 11070, 11080, 11090, 11…
$ premium <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ premium_partc <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ premium_partd <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …Final preparation for county-level analysis
ga_ma_2022is at the plan–county–year level (withavg_enrollment,premium_partc,avg_eligibles, etc.).
- To study how competition relates to premiums, we move to the county–year level and construct county-year level measures of premiums and competition
# Step 1: compute market shares within each county-year ------------------
# total_ma_enrollment and avg_eligibles come from the penetration file:
# avg_enrolled = total MA enrollment in the county
# avg_eligibles = total Medicare beneficiaries
ga_ma_2022_shares <- ga_ma_2022 %>%
group_by(fips, county, year) %>%
mutate(
total_ma_enrollment = first(avg_enrolled),
ma_share = if_else(
total_ma_enrollment > 0,
avg_enrollment / total_ma_enrollment,
NA_real_
)
) %>%
ungroup()
# Step 2: collapse to county-year level ---------------------------------
ga_county_2022 <- ga_ma_2022_shares %>%
group_by(fips, county, year) %>%
summarize(
# Competition: HHI = sum of squared MA shares
hhi_ma = sum(ma_share^2, na.rm = TRUE),
# Prices: simple average of Part C premiums across plans in the county
avg_premium_partc = mean(premium_partc, na.rm = TRUE),
# Count of plans with positive premium
n_pos_premiums = sum(premium_partc > 0, na.rm = TRUE),
# Premium range: max - min within county-year
premium_range = ifelse(
all(is.na(premium_partc)),
NA_real_,
max(premium_partc, na.rm = TRUE) - min(premium_partc, na.rm = TRUE)
),
# Total MA enrollment in the county (from penetration)
total_ma_enrollment = first(avg_enrolled),
# Total Medicare eligibles (from penetration)
avg_eligibles = first(avg_eligibles),
.groups = "drop"
)import numpy as np
import pandas as pd
# Step 1: compute market shares within each county-year ------------------
# total_ma_enrollment and avg_eligibles come from the penetration file:
# avg_enrolled = total MA enrollment in the county
# avg_eligibles = total Medicare beneficiaries
def add_shares(df):
total_ma = df["avg_enrolled"].iloc[0]
df = df.copy()
df["total_ma_enrollment"] = total_ma
df["ma_share"] = np.where(
total_ma > 0,
df["avg_enrollment"] / total_ma,
np.nan
)
return df
ga_ma_2022_shares = (
ga_ma_2022
.groupby(["fips", "county", "year"], group_keys=False)
.apply(add_shares)
)
# Step 2: collapse to county-year level ---------------------------------
ga_county_2022 = (
ga_ma_2022_shares
.groupby(["fips", "county", "year"], as_index=False)
.agg(
# HHI on MA shares
hhi_ma=("ma_share", lambda x: np.nansum(x**2)),
# Average premium
avg_premium_partc=("premium_partc", "mean"),
# Count of plans with positive premium
n_pos_premiums=("premium_partc", lambda x: (x > 0).sum()),
# Premium range: max - min
premium_range=("premium_partc", lambda x: x.max() - x.min()),
# Total MA enrollment (from penetration)
total_ma_enrollment=("avg_enrolled", "first"),
# Total Medicare eligibles (from penetration)
avg_eligibles=("avg_eligibles", "first"),
)
)Rows: 159
Columns: 9
$ fips <dbl> 13001, 13003, 13005, 13007, 13009, 13011, 13013, 1…
$ county <chr> "Appling", "Atkinson", "Bacon", "Baker", "Baldwin"…
$ year <dbl> 2022, 2022, 2022, 2022, 2022, 2022, 2022, 2022, 20…
$ hhi_ma <dbl> 0.02155152, 0.02328918, 0.02714814, 0.01953548, 0.…
$ avg_premium_partc <dbl> 3.864286, 0.000000, 5.422222, 0.000000, 3.188889, …
$ n_pos_premiums <int> 3, 0, 2, 0, 3, 2, 5, 1, 2, 1, 4, 2, 2, 1, 4, 1, 1,…
$ premium_range <dbl> 47.2, 0.0, 47.2, 0.0, 47.2, 47.2, 47.2, 47.2, 47.2…
$ total_ma_enrollment <dbl> 2190.0000, 798.5833, 1090.7500, 463.8333, 5504.916…
$ avg_eligibles <dbl> 3963.4167, 1370.3333, 2209.8333, 755.0833, 9245.83…New variables
- Total MA enrollment: \(\sum_j \text{avg_enrollment}_{j,cy}\)
- MA plan market shares: \[s_{j,cy} = \frac{\text{avg_enrollment}_{j,cy}}{\text{avg_enrolled}_{cy}}\], where
avg_enrolledcomes from the penetration file and represents total MA enrollment in the county.
- HHI: \(\sum_j s_{j,cy}^2\).
- Average premium: mean of
premium_partcacross plans in the county.
- Total eligibles:
avg_eligiblesfrom penetration data.
- Count of positive premiums: number of plans with
premium_partc > 0.
- Premium range: \(\max(\text{premium_partc}) - \min(\text{premium_partc})\) within county–year.
Plot premium and hhi
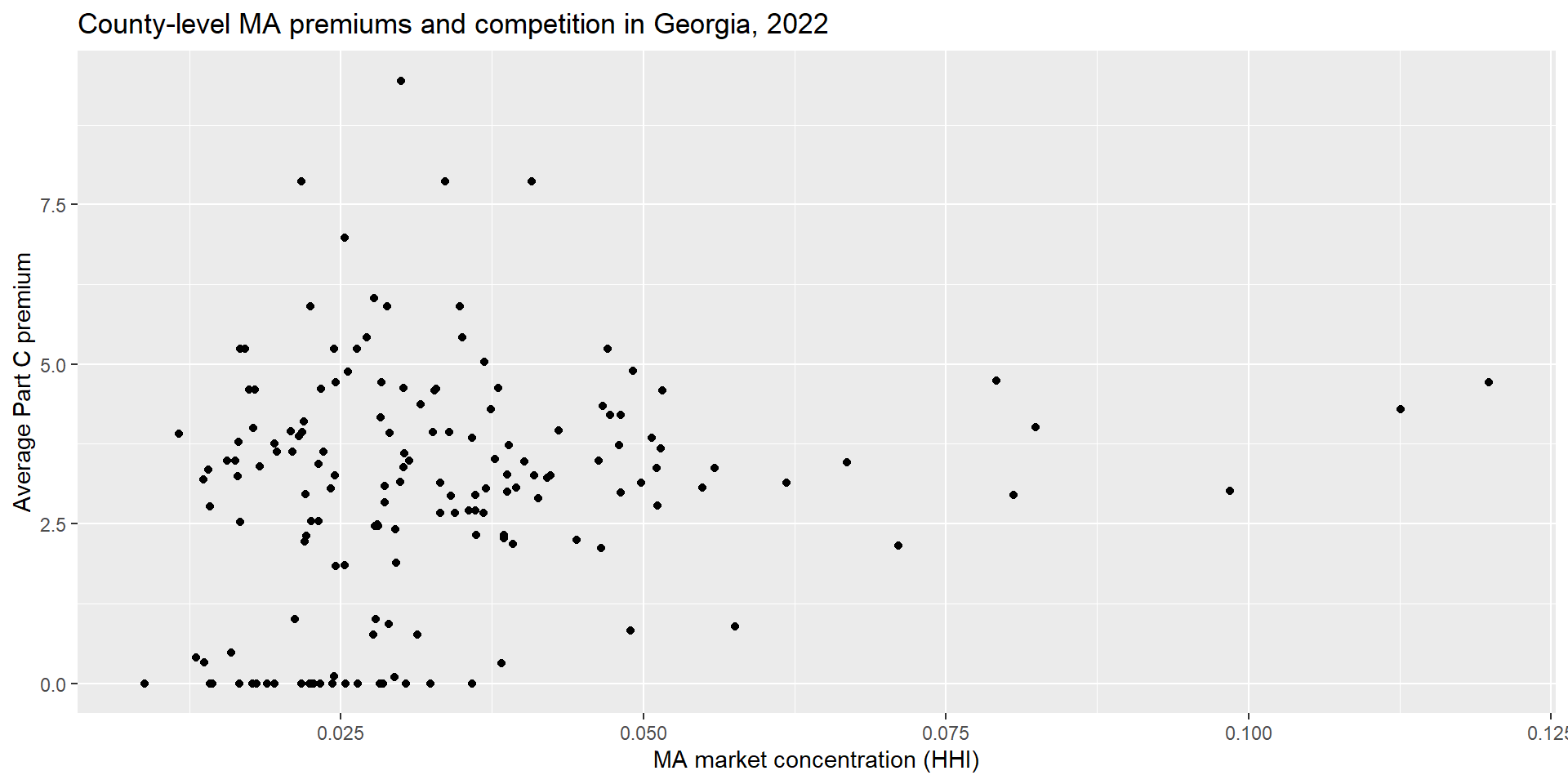
- As a simple descriptive exercise, we can plot average MA premiums against market concentration (HHI) at the county–year level.
- This doesn’t establish causality; it just helps visualize how more concentrated markets (higher HHI) line up with average premiums in our GA sample.