Estimate: \[\hat{\delta}_{ATE} = \frac{1}{N_{1}} \sum_{D_{i}=1} Y_{i} - \frac{1}{N_{0}} \sum_{D_{i}=0} Y_{i},\] where \(N_{1}\) is number of treated and \(N_{0}\) is number untreated (control)
“Selection” or “self-selection” sometimes used to describe process of missing data (e.g., people “self-select” into the labor market)
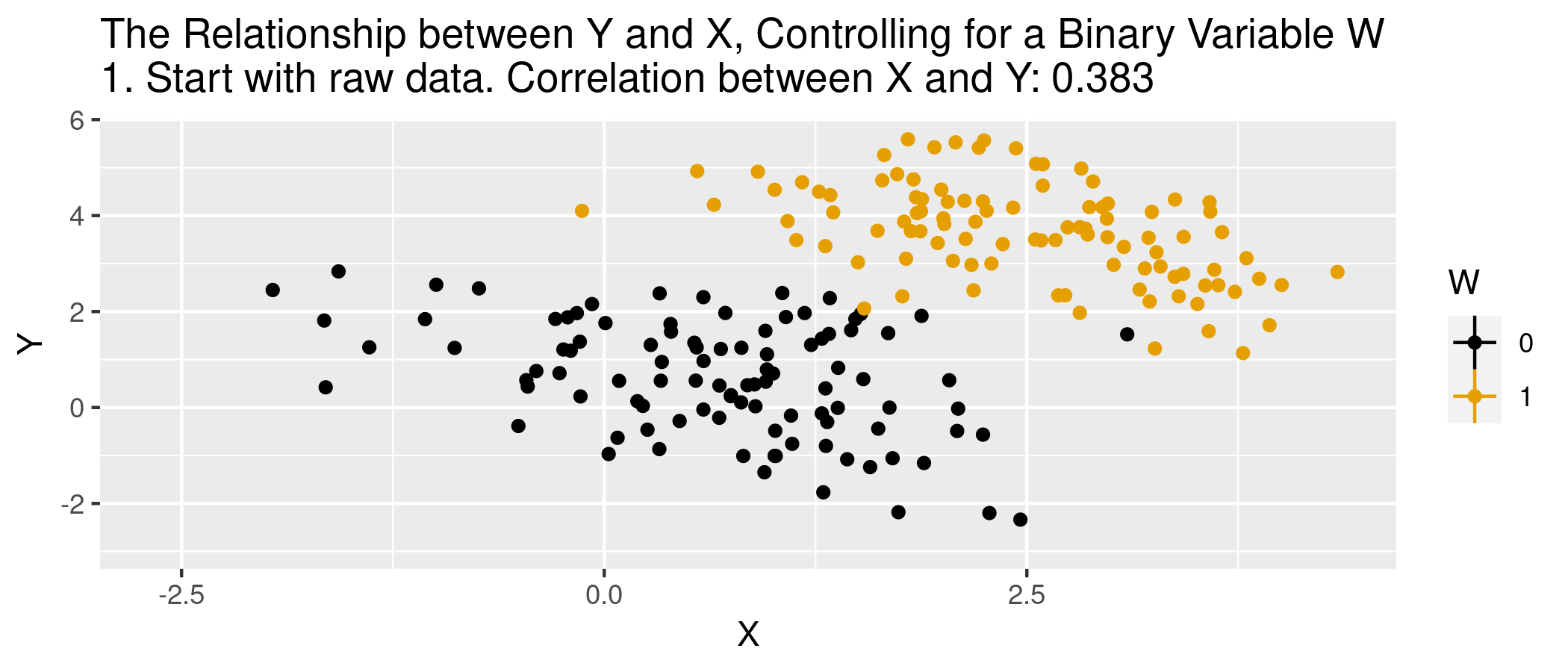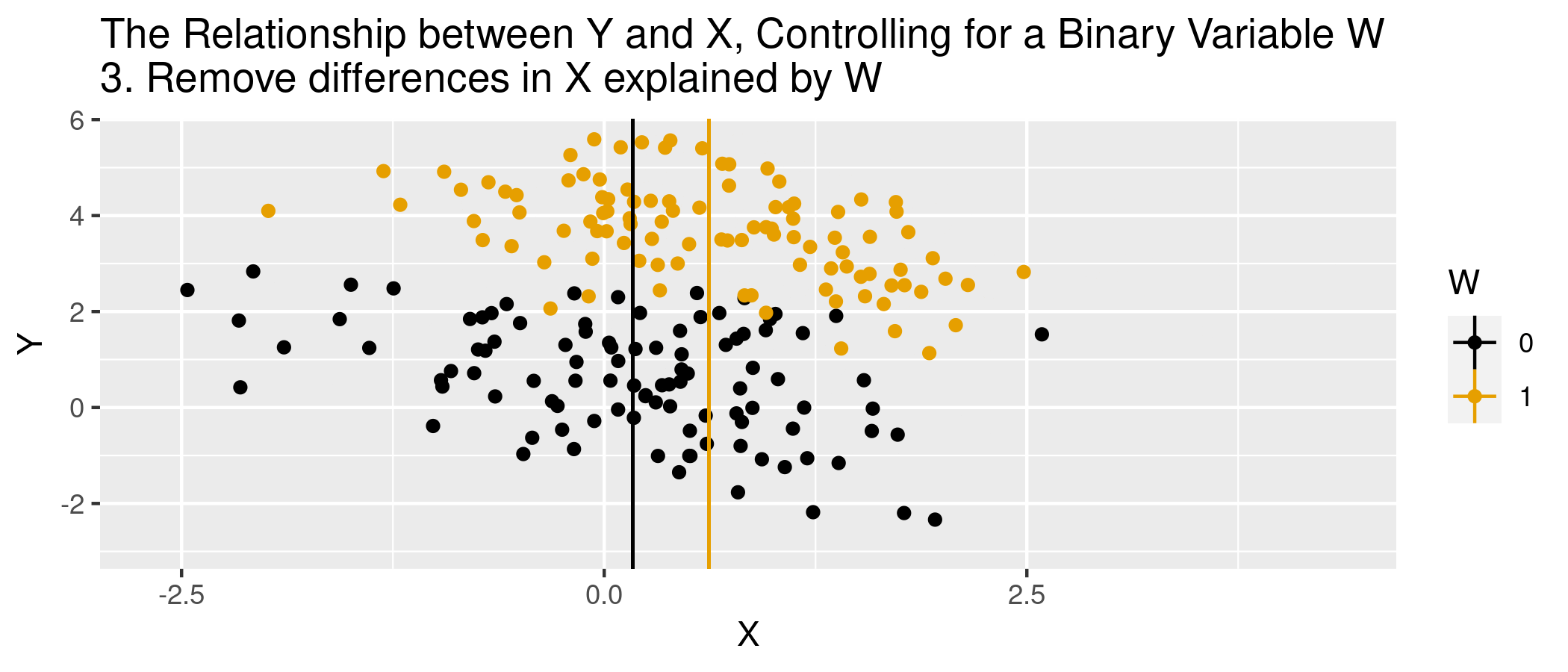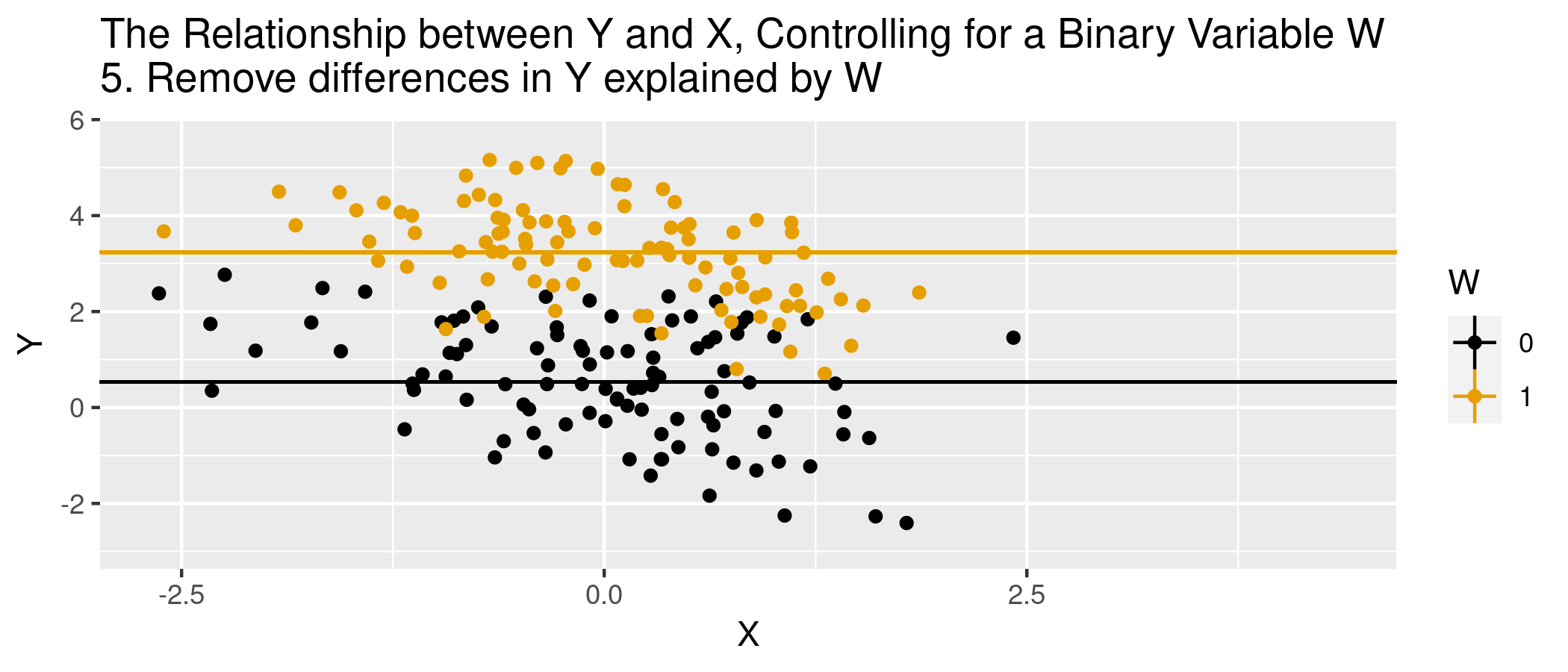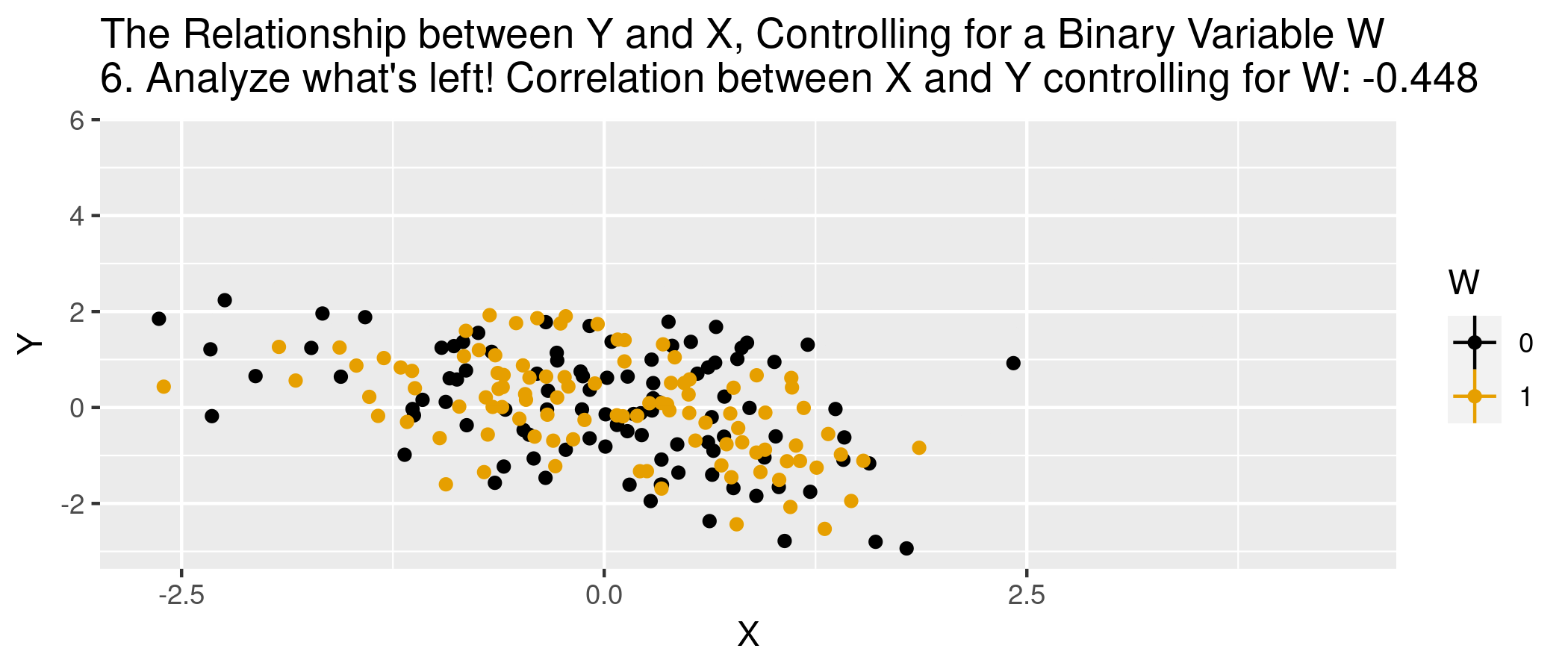
We’re using “selection” differently…captures process by which units are associated with specific values of covariates (e.g., in a study of hospital admits and health, patients are in the hospital because of unobserved things also related to their health)
Potential Solution…
Find covariates \(X_{i}\) such that the following assumptions are plausible:
Selection on observables: \[Y_{0i}, Y_{1i} \perp\!\!\!\perp D_{i} | X_{i}\]
Common support: \[0 < \text{Pr}(D_{i}=1|X_{i}) < 1\]
KEY INTUITION: My potential outcomes are unchanged by treatment status…treatment status governs which potential outcome is observed in the data
Then we can use \(X_{i}\) to group observations and use expected values from control group as the predicted counterfactuals among treated, and vice versa.
Assumption 1: Selection on Observables
\(E[Y_{1}|D,X]=E[Y_{1}|X]\)
In words…nothing else, outside of \(X\), that determines treatment selection and affects your outcome of interest.
Assumption 2: Common Support
Someone of each type must be in both the treated and untreated groups
\[0 < \text{Pr}(D=1|X) <1\]
Estimators Based on Selection on Observables Assumption
With selection on observables and common support:
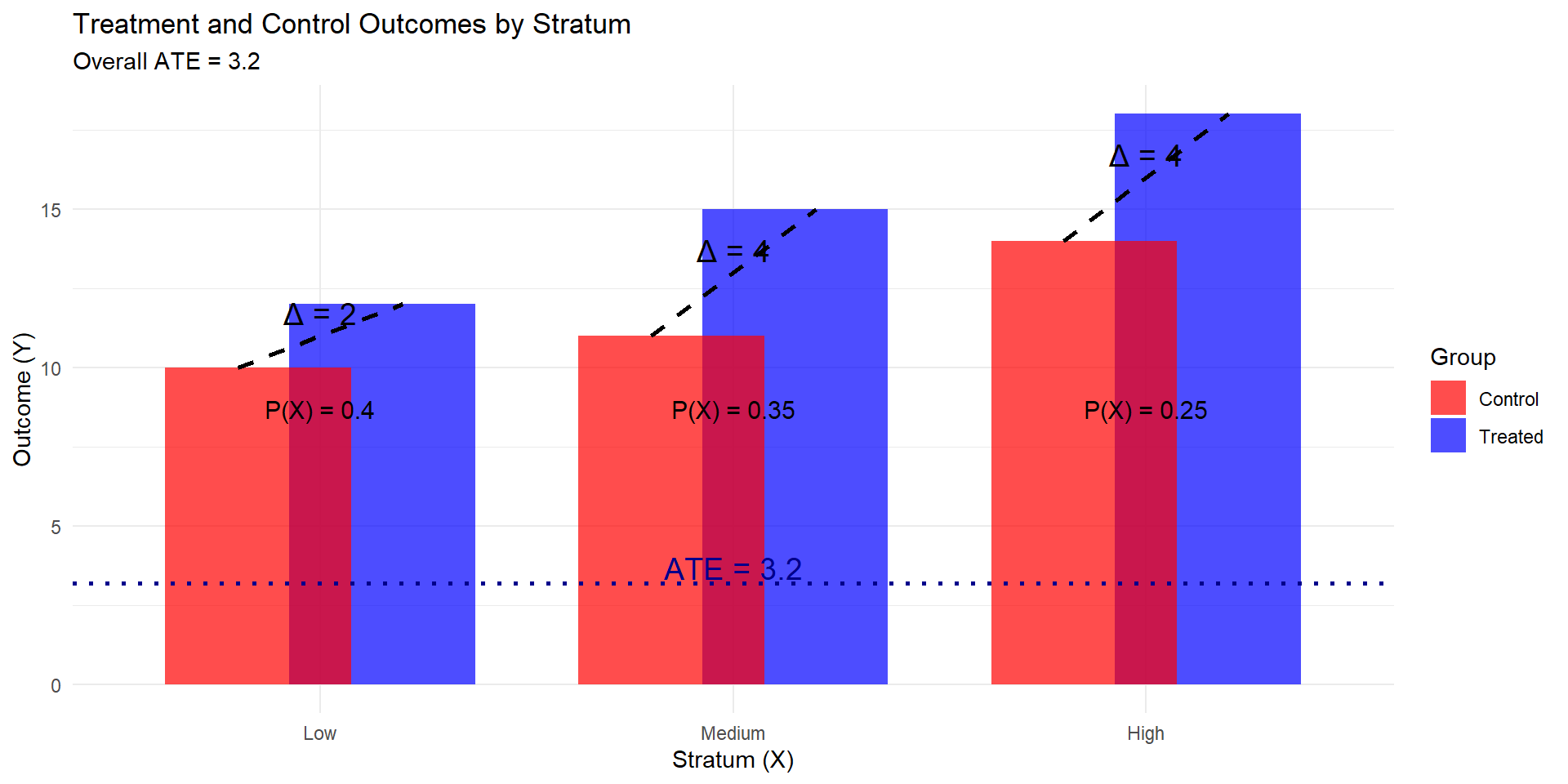
Subclassification
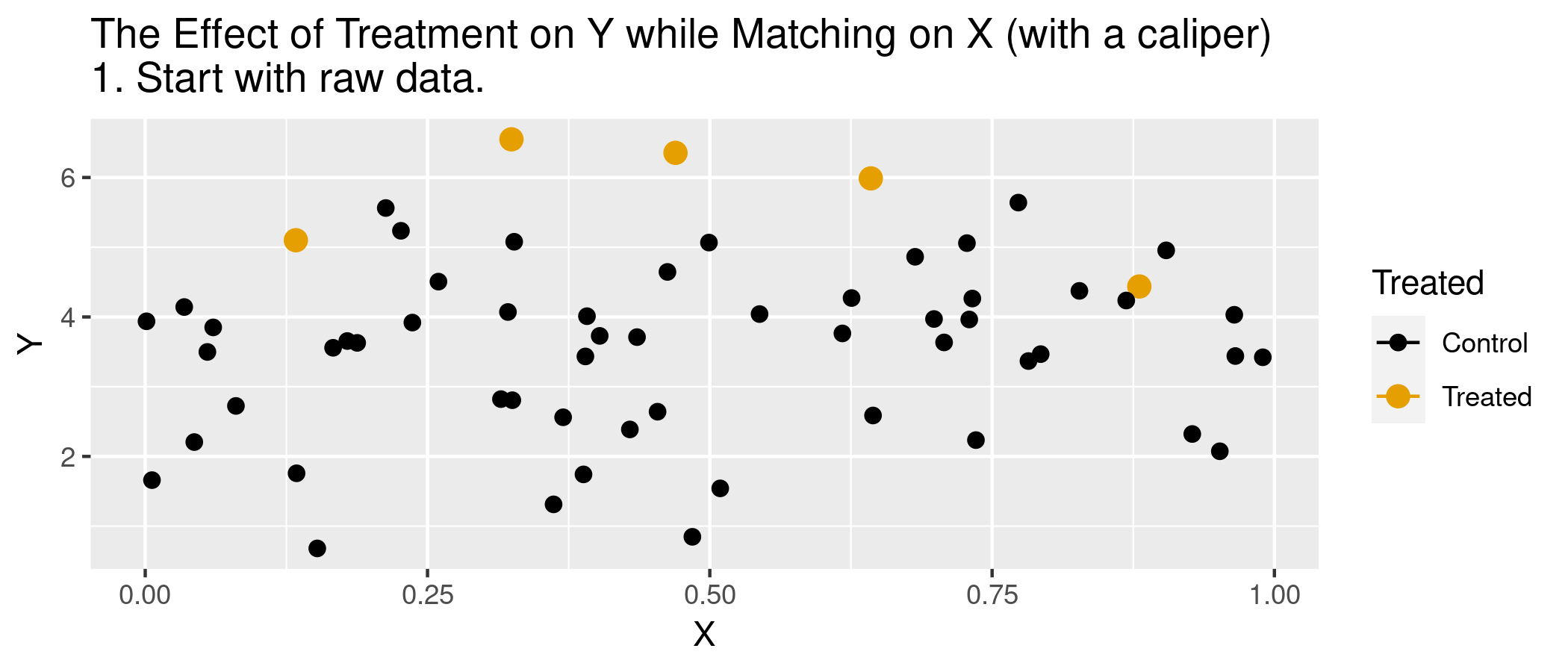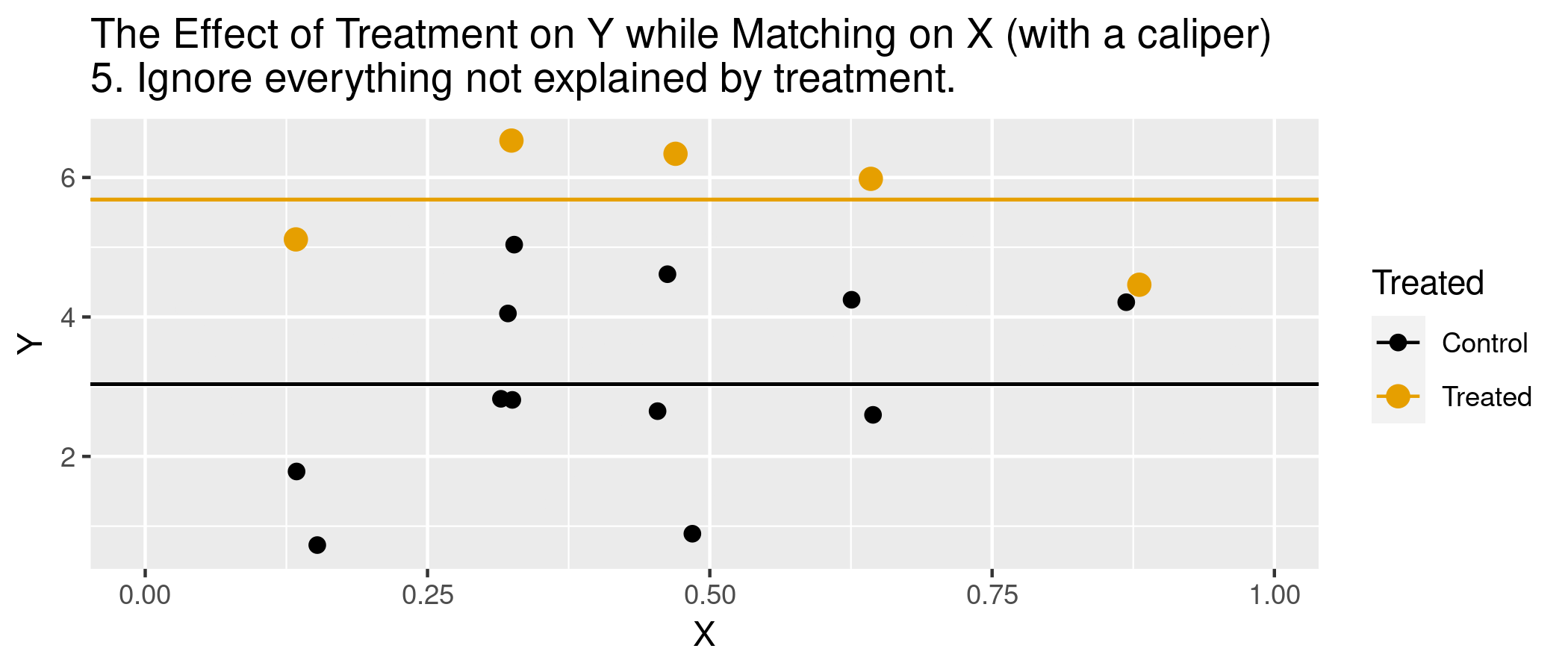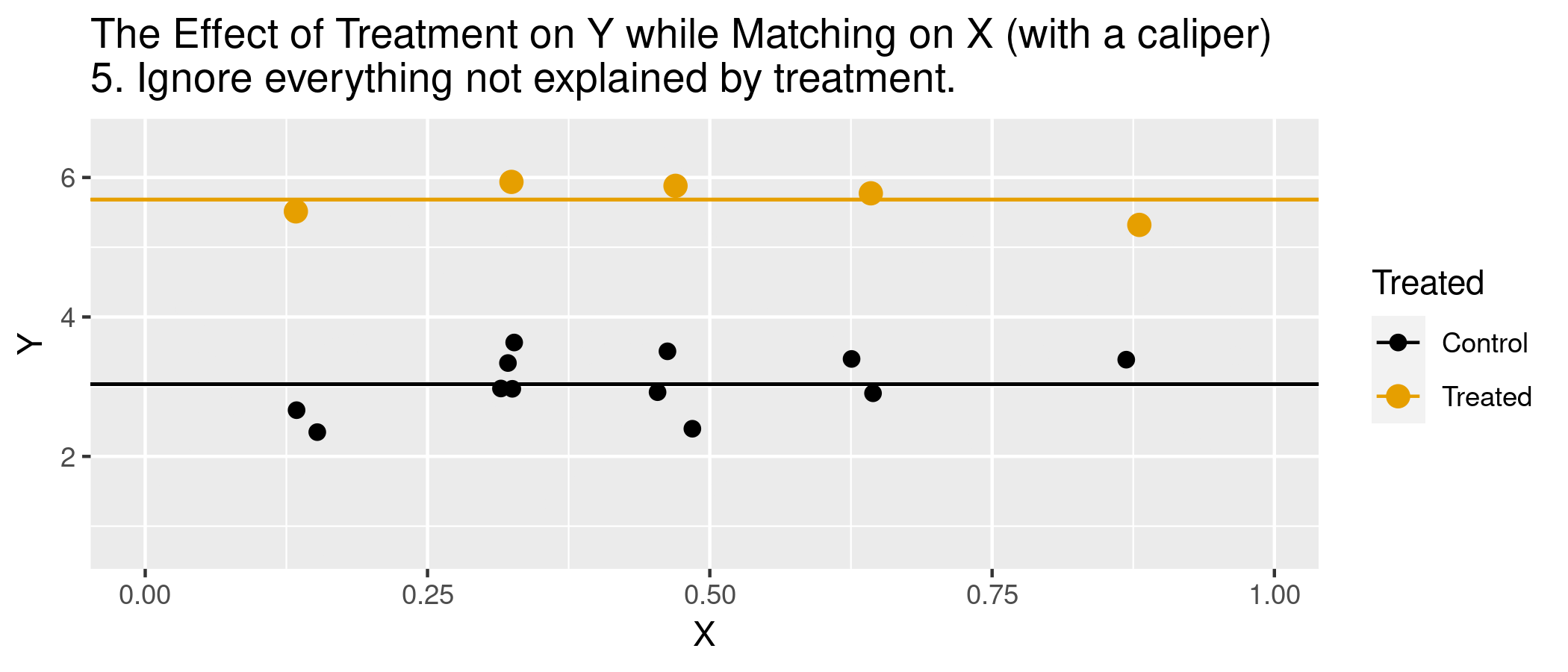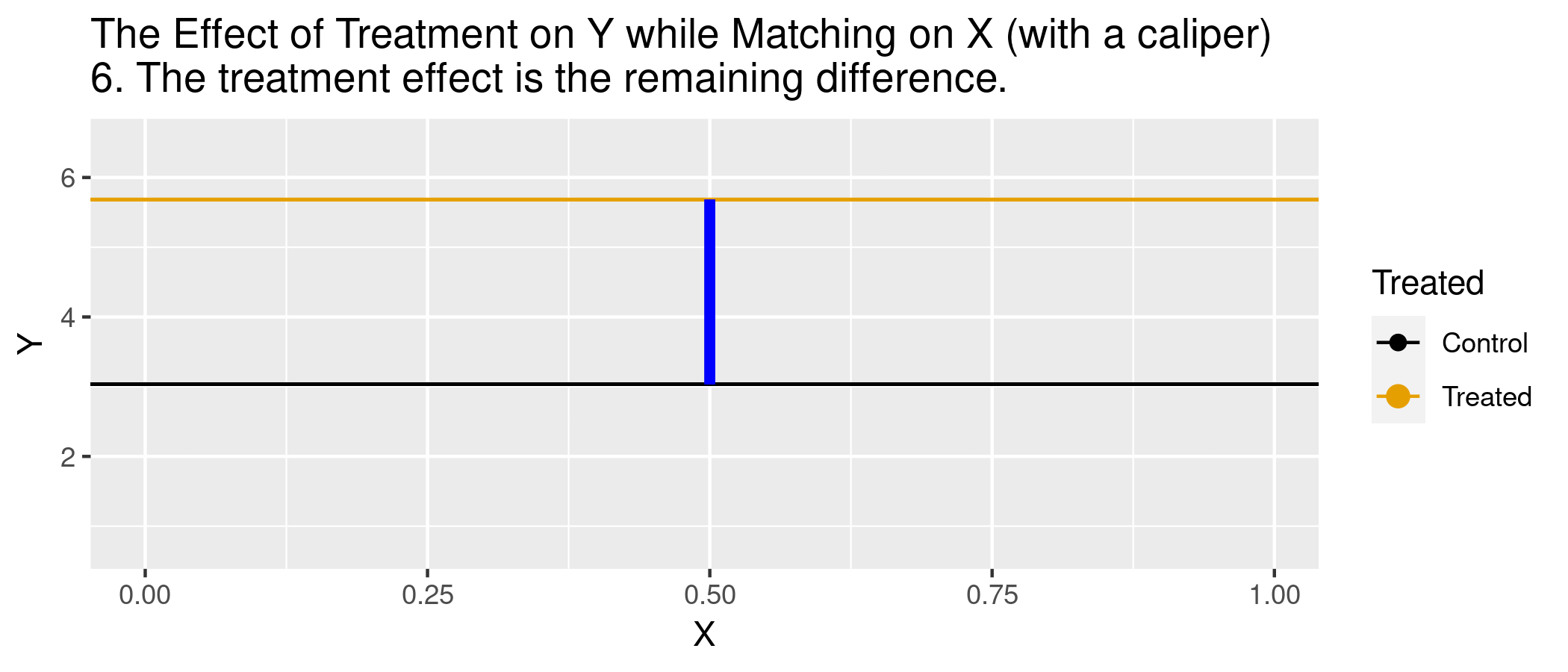
Matching estimators
Reweighting estimators
Regression estimators
Subclassification
Sum the average treatment effects by group, and take a weighted average over those groups:
But are observations really the same in each group? Potential for “matching discrepancies” to introduce bias in estimates
“Bias correction” based on \[\hat{\mu}(x_{i}) - \hat{\mu}(x_{j(i)})\] (i.e., difference in fitted values from regression of \(y\) on \(x\), with the difference between observed \(Y_{1i}\) and imputed \(Y_{0i}\))
\(\hat{\mu}(x_{i})\) is the predicted outcome from a regression of \(Y\) on \(X\).
\(x_{i}\) is the covariate vector for a treated unit.
\(x_{j(i)}\) is the covariate vector for its matched control.
!pip install rpy2%load_ext rpy2.ipython%%R -i select_dat# select_dat is now an R data.frameif (!requireNamespace("Matching", quietly = TRUE)) { install.packages("Matching")}library(Matching)nn.est1 <- Matching::Match( Y = select_dat$y, Tr = select_dat$w, X = select_dat$x, M =1, Weight =1, estimand ="ATE")summary(nn.est1)%%R -o nn.est1
Estimate... 5.2219
AI SE...... 0.73392
T-stat..... 7.1151
p.val...... 1.118e-12
Original number of observations.............. 5000
Original number of treated obs............... 1764
Matched number of observations............... 5000
Matched number of observations (unweighted). 5012
Simulation: nearest neighbor matching with Mahalanobis
!pip install rpy2%load_ext rpy2.ipython%%R -i select_dat# select_dat is now an R data.frameif (!requireNamespace("Matching", quietly = TRUE)) { install.packages("Matching")}library(Matching)nn.est2 <- Matching::Match( Y = select_dat$y, Tr = select_dat$w, X = select_dat$x, M =1, Weight =2, estimand ="ATE")summary(nn.est1)%%R -o nn.est2
Estimate... 5.2219
AI SE...... 0.73392
T-stat..... 7.1151
p.val...... 1.118e-12
Original number of observations.............. 5000
Original number of treated obs............... 1764
Matched number of observations............... 5000
Matched number of observations (unweighted). 5012
Estimate... 7.6158
AI SE...... 0.052728
T-stat..... 144.44
p.val...... < 2.22e-16
Original number of observations.............. 5000
Original number of treated obs............... 2762
Matched number of observations............... 5000
Matched number of observations (unweighted). 22537