ga_ma_2022 <- read_csv("../data/output/ma-snippets/ga-ma-data-2022.csv") %>%
group_by(fips) %>%
mutate(
total_ma_enrollment = first(avg_enrolled),
ma_share = if_else(
total_ma_enrollment > 0,
(avg_enrollment / total_ma_enrollment) * 100,
NA_real_
)
) %>%
summarize(
hhi_ma = sum(ma_share^2, na.rm = TRUE),
plan_count = n_distinct(contractid, planid),
avg_premium_partc = mean(premium_partc, na.rm = TRUE),
share_pos_premiums = mean(premium_partc > 0, na.rm = TRUE),
avg_bid = mean(bid, na.rm = TRUE),
avg_eligibles = first(avg_eligibles),
ffs_cost = first(avg_ffscost)
) %>%
ungroup()Matching and Weighting IRL
Assessing Balance
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
covariates = [
"avg_eligibles",
"ffs_cost",
]
lp_vars = ga_tab[["hhi_group"] + covariates].dropna()
treated = lp_vars[lp_vars["hhi_group"] == "treated"]
control = lp_vars[lp_vars["hhi_group"] == "control"]
# -------------------------------------------------------------------
# Standardized mean differences (treated – control)
# SMD = (m1 - m0) / sqrt((s1^2 + s0^2)/2)
# -------------------------------------------------------------------
def smd(x_t, x_c):
m1, m0 = x_t.mean(), x_c.mean()
v1, v0 = x_t.var(ddof=1), x_c.var(ddof=1)
return (m1 - m0) / np.sqrt((v1 + v0) / 2)
smd_list = []
for var in covariates:
smd_val = smd(treated[var], control[var])
smd_list.append({"variable": var, "smd": smd_val})
smd_df = pd.DataFrame(smd_list)
smd_df["abs_smd"] = smd_df["smd"].abs()
# Optional: nicer labels
rename_map = {
"avg_eligibles" : "Avg eligibles",
"ffs_cost" : "Avg FFS cost",
}
smd_df["label"] = smd_df["variable"].replace(rename_map)
# Sort by absolute SMD for a nicer plot
smd_df = smd_df.sort_values("abs_smd")
# -------------------------------------------------------------------
# “Love plot” using matplotlib
# -------------------------------------------------------------------
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(smd_df["smd"], smd_df["label"])
# Reference lines at 0 and +/- 0.1
ax.axvline(0.0, color="black", linewidth=1)
ax.axvline(0.1, color="grey", linestyle="--", linewidth=1)
ax.axvline(-0.1, color="grey", linestyle="--", linewidth=1)
ax.set_xlabel("Standardized mean difference (treated - control)")
ax.set_ylabel("Covariate")
ax.set_title("Covariate balance by HHI treatment status")
plt.tight_layout()
plt.show()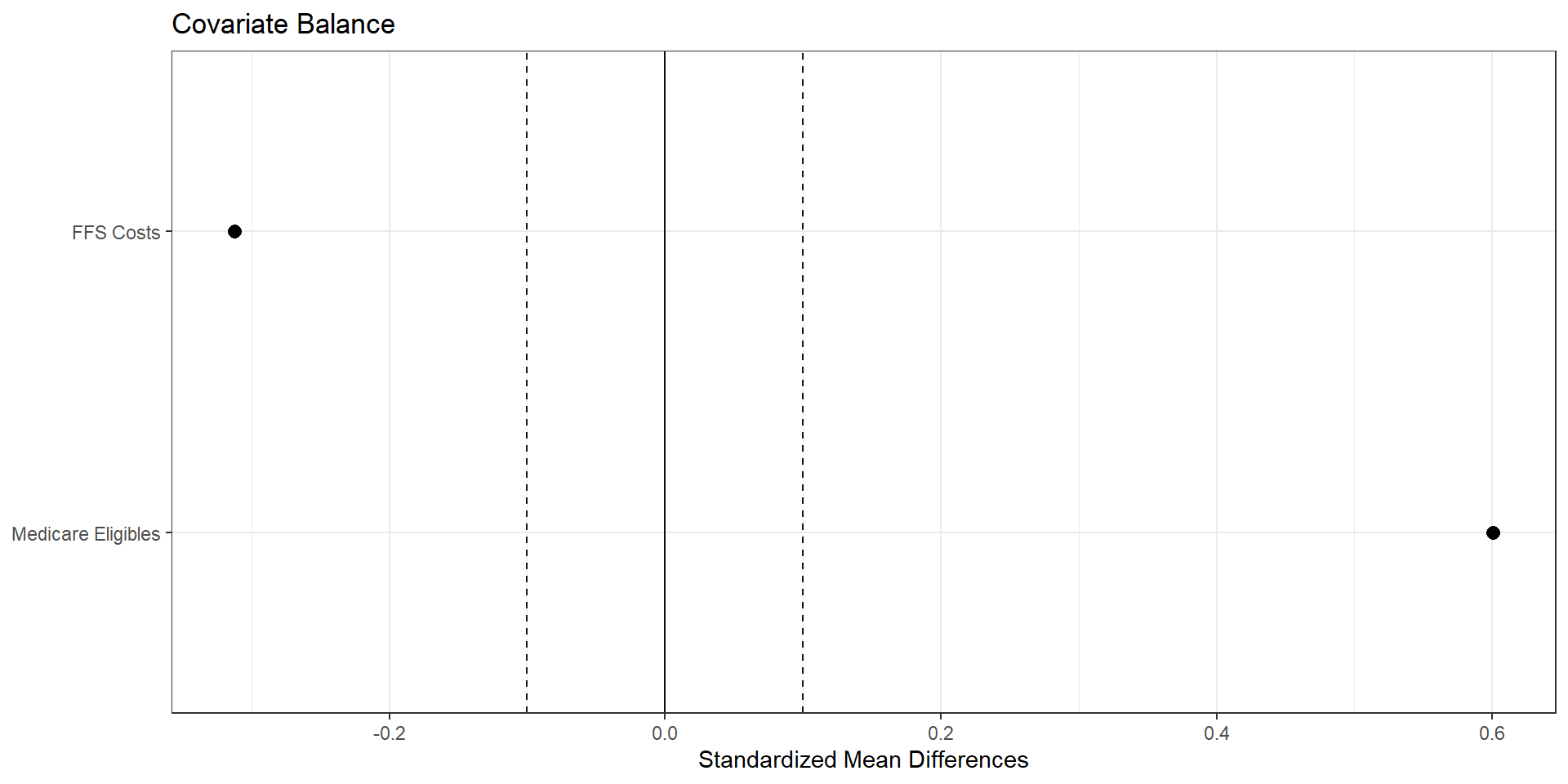
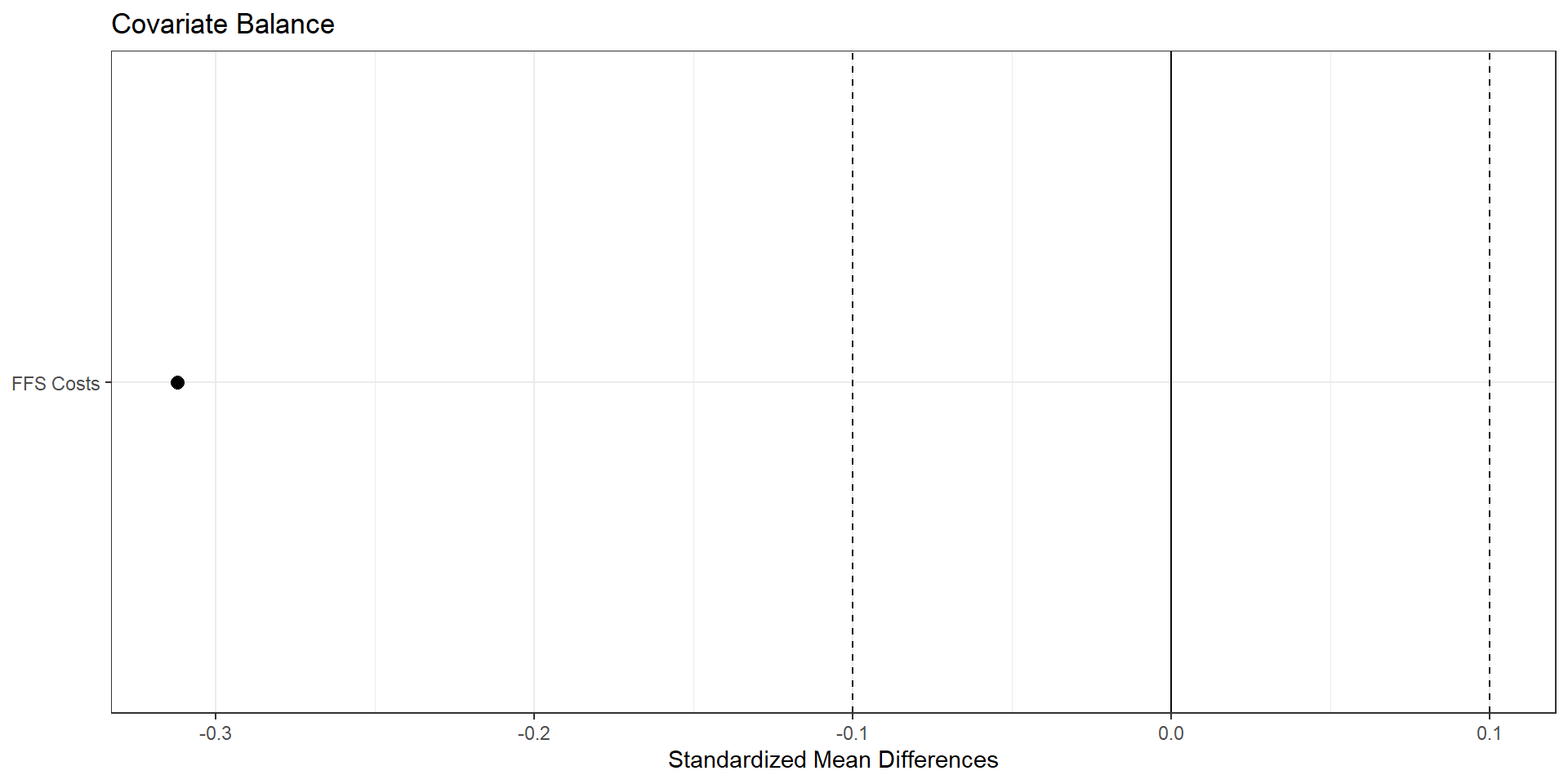
1. Exact Matching (on a subset)
2. Nearest neighbor matching (inverse variance, many matches)
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import NearestNeighbors
# lp_df should contain:
# - 'avg_bid' (outcome, like Y)
# - 'treated_dummy' (0/1, like Tr)
# - all columns in lp.covs (covariates for matching)
cov_cols = [
"avg_eligibles",
"ffs_cost",
]
# Drop missing
lp_df_cc = lp_df.dropna(subset=cov_cols + ["avg_bid", "treated_dummy"]).copy()
treated = lp_df_cc[lp_df_cc["treated_dummy"] == 1].copy()
controls = lp_df_cc[lp_df_cc["treated_dummy"] == 0].copy()
X_t = treated[cov_cols].values
X_c = controls[cov_cols].values
y_t = treated["avg_bid"].values
y_c = controls["avg_bid"].values
# Standardize covariates (rough analogue to Weight=1 / inverse-variance scaling)
scaler = StandardScaler()
X_c_scaled = scaler.fit_transform(X_c)
X_t_scaled = scaler.transform(X_t)
# Nearest neighbors: M = 4 matches per treated
M = 4
nn = NearestNeighbors(n_neighbors=M, metric="euclidean")
nn.fit(X_c_scaled)
distances, indices = nn.kneighbors(X_t_scaled, return_distance=True)
# For each treated unit, average its matched controls' outcomes
matched_ctrl_means = y_c[indices].mean(axis=1)
# ATT-style estimate: E[Y(1) - Y(0) | treated]
effect_nn = np.mean(y_t - matched_ctrl_means)
print("Nearest-neighbor estimate for avg_bid (treated - control):", effect_nn)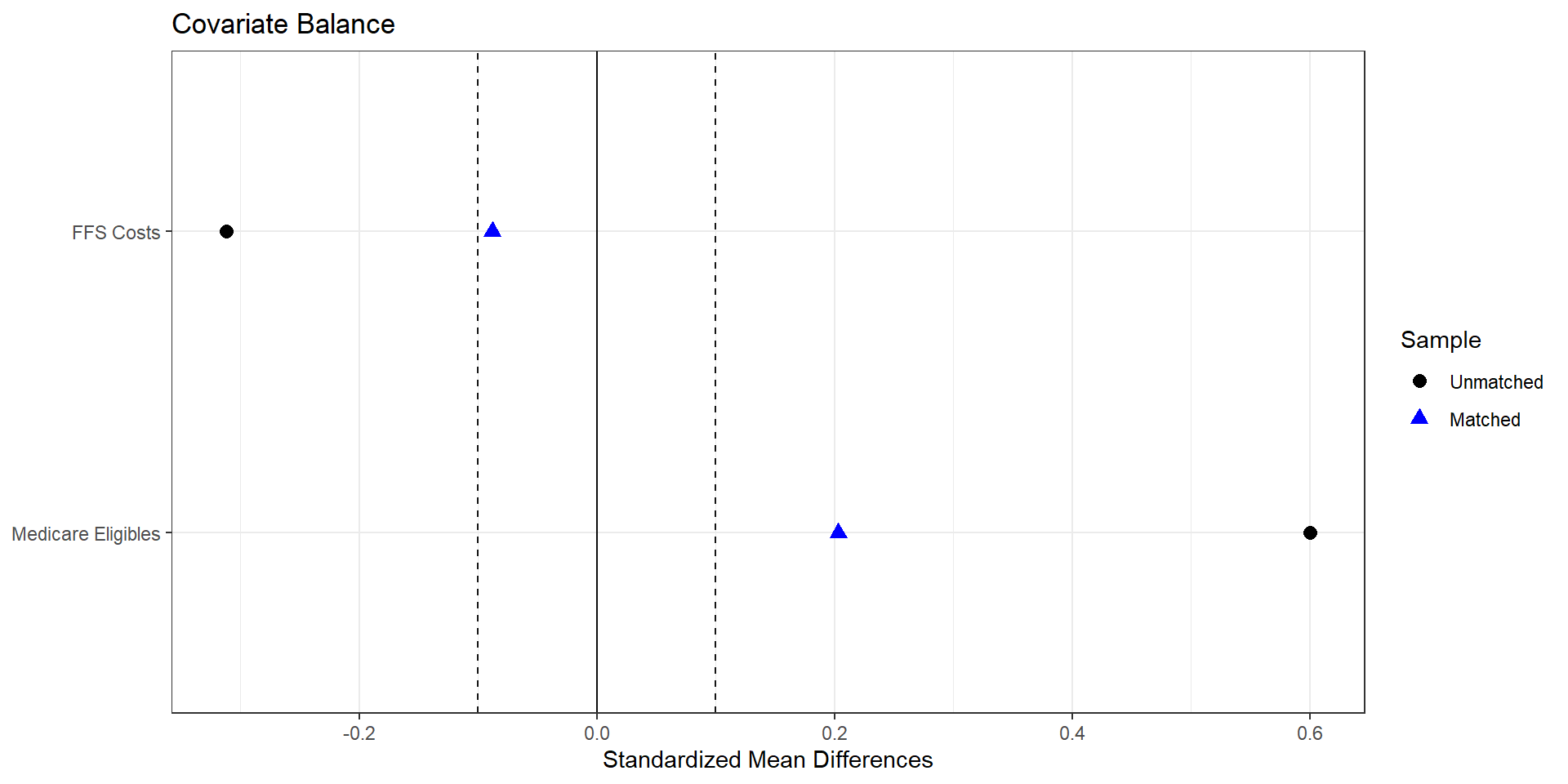
Estimate... 11.133
AI SE...... 3.7953
T-stat..... 2.9333
p.val...... 0.003354
Original number of observations.............. 107
Original number of treated obs............... 54
Matched number of observations............... 107
Matched number of observations (unweighted). 428 2. Nearest neighbor matching (inverse variance, one-to-one)
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import NearestNeighbors
# lp_df should contain:
# - 'avg_bid' (outcome, like Y)
# - 'treated_dummy' (0/1, like Tr)
# - all columns in lp.covs (covariates for matching)
cov_cols = [
"avg_eligibles",
"ffs_cost",
]
# Drop missing
lp_df_cc = lp_df.dropna(subset=cov_cols + ["avg_bid", "treated_dummy"]).copy()
treated = lp_df_cc[lp_df_cc["treated_dummy"] == 1].copy()
controls = lp_df_cc[lp_df_cc["treated_dummy"] == 0].copy()
X_t = treated[cov_cols].values
X_c = controls[cov_cols].values
y_t = treated["avg_bid"].values
y_c = controls["avg_bid"].values
# Standardize covariates (rough analogue to Weight=1 / inverse-variance scaling)
scaler = StandardScaler()
X_c_scaled = scaler.fit_transform(X_c)
X_t_scaled = scaler.transform(X_t)
# Nearest neighbors: M = 1 match per treated
M = 1
nn = NearestNeighbors(n_neighbors=M, metric="euclidean")
nn.fit(X_c_scaled)
distances, indices = nn.kneighbors(X_t_scaled, return_distance=True)
# For each treated unit, average its matched controls' outcomes
matched_ctrl_means = y_c[indices].mean(axis=1)
# ATT-style estimate: E[Y(1) - Y(0) | treated]
effect_nn = np.mean(y_t - matched_ctrl_means)
print("Nearest-neighbor estimate for avg_bid (treated - control):", effect_nn)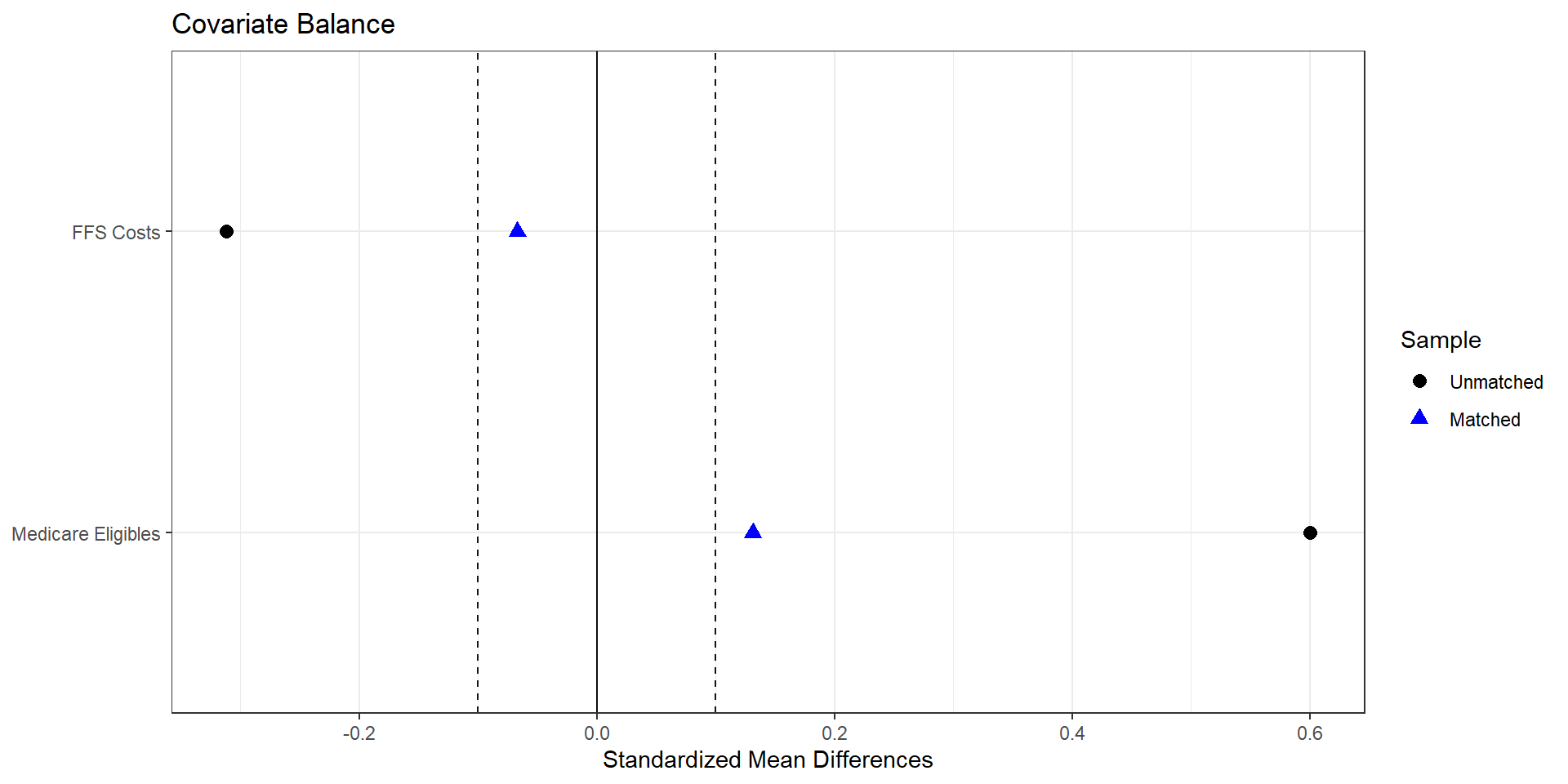
Estimate... 11.726
AI SE...... 4.3248
T-stat..... 2.7114
p.val...... 0.0067009
Original number of observations.............. 107
Original number of treated obs............... 54
Matched number of observations............... 107
Matched number of observations (unweighted). 107 2. Nearest neighbor matching (Mahalanobis)
import numpy as np
import pandas as pd
from sklearn.neighbors import NearestNeighbors
# Covariate set X (matching variables)
cov_cols = [
"avg_eligibles",
"ffs_cost",
]
# Drop missing on outcome / treatment / covariates
lp_df_cc = lp_df.dropna(subset=cov_cols + ["avg_bid", "treated_dummy"]).copy()
treated = lp_df_cc[lp_df_cc["treated_dummy"] == 1].copy()
controls = lp_df_cc[lp_df_cc["treated_dummy"] == 0].copy()
X_t = treated[cov_cols].to_numpy()
X_c = controls[cov_cols].to_numpy()
y_t = treated["avg_bid"].to_numpy()
y_c = controls["avg_bid"].to_numpy()
# Pooled covariance of covariates (R's Matching uses Mahalanobis on X)
V = np.cov(np.vstack([X_t, X_c]).T)
# 1-nearest neighbor with Mahalanobis distance --------------------------
nn = NearestNeighbors(
n_neighbors=1,
metric="mahalanobis",
metric_params={"V": V}
)
nn.fit(X_c)
distances, indices = nn.kneighbors(X_t, return_distance=True)
# Matched control outcomes
matched_ctrl = y_c[indices.flatten()]
# ATT-style effect (treated minus matched controls)
effect_nn_md = np.mean(y_t - matched_ctrl)
print("Mahalanobis 1-NN estimate for avg_bid (treated - control):", effect_nn_md)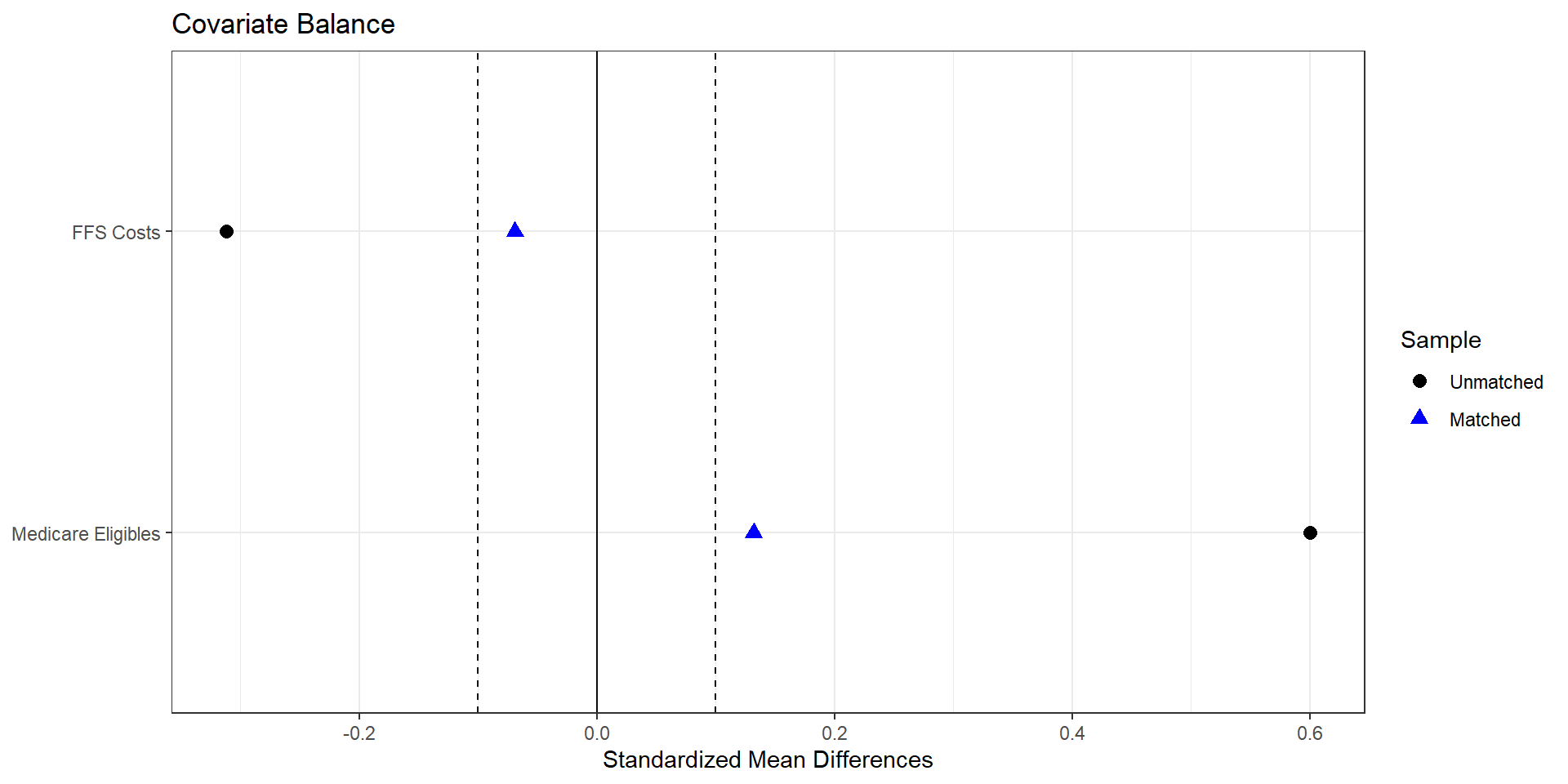
Estimate... 11.416
AI SE...... 4.3543
T-stat..... 2.6217
p.val...... 0.0087482
Original number of observations.............. 107
Original number of treated obs............... 54
Matched number of observations............... 107
Matched number of observations (unweighted). 107 2. Nearest neighbor matching (propensity score)
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
from sklearn.neighbors import NearestNeighbors
# lp_df should contain:
# - 'avg_bid' (outcome)
# - 'treated_dummy' (0/1)
# - 'avg_eligibles'
# - 'ffs_cost' # use 'ffs_cost' here if that's your column name
# 1. Estimate propensity scores ----------------------------------------
logit_res = smf.logit(
"treated_dummy ~ avg_eligibles + ffs_cost",
data=lp_df
).fit()
lp_df_ps = lp_df.copy()
lp_df_ps["ps"] = logit_res.predict(lp_df_ps)
# Optional: trim extreme PS
eps = 1e-6
lp_df_ps["ps"] = lp_df_ps["ps"].clip(eps, 1 - eps)
# 2. Prepare treated / control samples ---------------------------------
lp_df_cc = lp_df_ps.dropna(subset=["avg_bid", "treated_dummy", "ps"]).copy()
treated = lp_df_cc[lp_df_cc["treated_dummy"] == 1].copy()
controls = lp_df_cc[lp_df_cc["treated_dummy"] == 0].copy()
y_t = treated["avg_bid"].to_numpy()
y_c = controls["avg_bid"].to_numpy()
X_t = treated[["ps"]].to_numpy() # 1D propensity score as matching covariate
X_c = controls[["ps"]].to_numpy()
# 3. 1-nearest neighbor on propensity score (ATT-style) ----------------
nn = NearestNeighbors(n_neighbors=1, metric="euclidean")
nn.fit(X_c)
distances, indices = nn.kneighbors(X_t, return_distance=True)
matched_ctrl = y_c[indices.flatten()]
effect_ps_nn = np.mean(y_t - matched_ctrl)
print("PS 1-NN estimate for avg_bid (treated - control):", effect_ps_nn)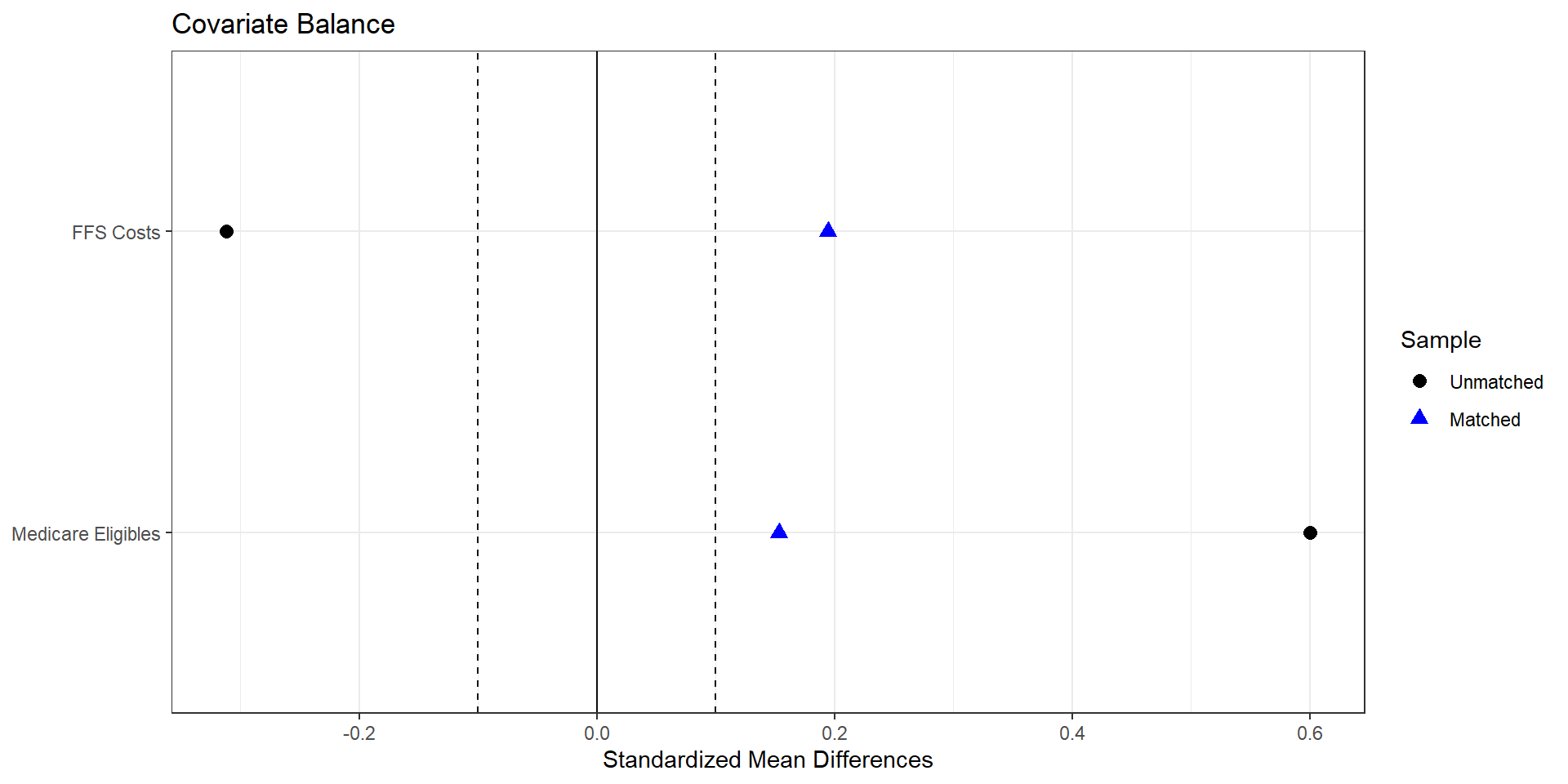
Estimate... 13.097
AI SE...... 4.6112
T-stat..... 2.8402
p.val...... 0.0045081
Original number of observations.............. 107
Original number of treated obs............... 54
Matched number of observations............... 107
Matched number of observations (unweighted). 108 3. Weighting with Simple Averages
lp.vars <- lp.vars %>%
mutate(ipw = case_when(
treated_dummy==1 ~ 1/ps,
treated_dummy==0 ~ 1/(1-ps),
TRUE ~ NA_real_
))
mean.t1 <- lp.vars %>% filter(treated_dummy==1) %>%
select(avg_bid, ipw) %>% summarize(mean_bid=weighted.mean(avg_bid,w=ipw))
mean.t0 <- lp.vars %>% filter(treated_dummy==0) %>%
select(avg_bid, ipw) %>% summarize(mean_bid=weighted.mean(avg_bid,w=ipw))import numpy as np
import pandas as pd
p_vars = lp_df.copy()
# Inverse probability weights
p_vars["ipw"] = np.where(
p_vars["treated_dummy"] == 1,
1.0 / p_vars["ps"],
1.0 / (1.0 - p_vars["ps"])
)
# Treated group weighted mean of avg_bid
treated = p_vars[p_vars["treated_dummy"] == 1]
mean_t1 = np.average(treated["avg_bid"], weights=treated["ipw"])
# Control group weighted mean of avg_bid
controls = p_vars[p_vars["treated_dummy"] == 0]
mean_t0 = np.average(controls["avg_bid"], weights=controls["ipw"])
ate_ipw = mean_t1 - mean_t0
print("IPW mean (treated):", mean_t1)
print("IPW mean (control):", mean_t0)
print("IPW ATE (treated - control):", ate_ipw)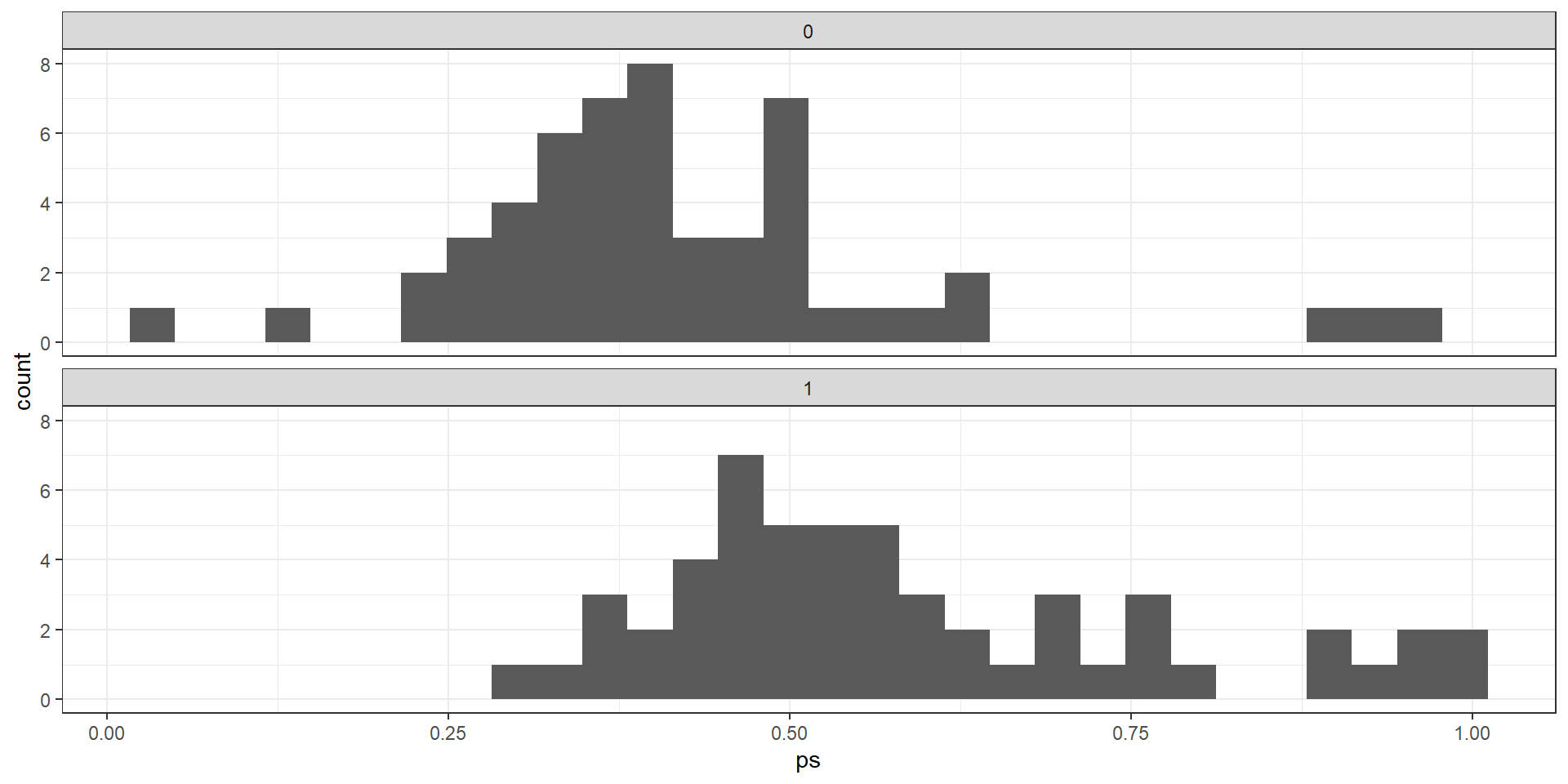
[1] 6.301051