ga_ma_2022 <- read_csv("../data/output/ma-snippets/ga-ma-data-2022.csv") %>%
select(-partc_score) %>% ungroup()
ma_ratings <- read_csv("../data/output/ma-snippets/ga-ratings-2022.csv")
ga_ma_full <- ga_ma_2022 %>%
left_join(ma_ratings, by="contractid") %>%
mutate(raw_rating=rowMeans(
cbind(breastcancer_screen, rectalcancer_screen, flu_vaccine,
physical_monitor, specialneeds_manage, older_medication, older_pain,
osteo_manage, diabetes_eye, diabetes_kidney, diabetes_bloodsugar,
ra_manage, falling, bladder, medication, statin, nodelays,
carequickly, customer_service, overallrating_care, overallrating_plan,
coordination, complaints_plan, leave_plan, improve, appeals_timely,
appeals_review, ttyt_available),
na.rm=T)) %>%
select(contractid, planid, fips, plan_type, partd, avg_enrollment, avg_eligibles,
avg_enrolled, premium, premium_partc, premium_partd, rebate_partc, ma_rate,
bid, avg_ffscost, partc_score, partcd_score, raw_rating)More Medicare Advantage Data
Example: Star Ratings in 2022
import pandas as pd
# Read in data
ga_ma_2022 = (
pd.read_csv("../data/output/ma-snippets/ga-ma-data-2022.csv")
.drop(columns=["partc_score"], errors="ignore")
)
ma_ratings = pd.read_csv("../data/output/ma-snippets/ga-ratings-2022.csv")
# Merge on contractid
ga_ma_full = ga_ma_2022.merge(ma_ratings, on="contractid", how="left")
# Variables used to construct the raw rating
rating_vars = [
"breastcancer_screen", "rectalcancer_screen", "flu_vaccine",
"physical_monitor", "specialneeds_manage", "older_medication", "older_pain",
"osteo_manage", "diabetes_eye", "diabetes_kidney", "diabetes_bloodsugar",
"ra_manage", "falling", "bladder", "medication", "statin", "nodelays",
"carequickly", "customer_service", "overallrating_care", "overallrating_plan",
"coordination", "complaints_plan", "leave_plan", "improve", "appeals_timely",
"appeals_review", "ttyt_available"
]
# Row-wise mean, ignoring missing values (na.rm = TRUE)
ga_ma_full["raw_rating"] = ga_ma_full[rating_vars].mean(axis=1, skipna=True)
# Keep the desired columns
ga_ma_full = ga_ma_full[
[
"contractid", "planid", "fips", "plan_type", "partd", "avg_enrollment",
"avg_eligibles", "avg_enrolled", "premium", "premium_partc",
"premium_partd", "rebate_partc", "ma_rate", "bid", "avg_ffscost",
"partc_score", "partcd_score", "raw_rating"
]
]
R Code
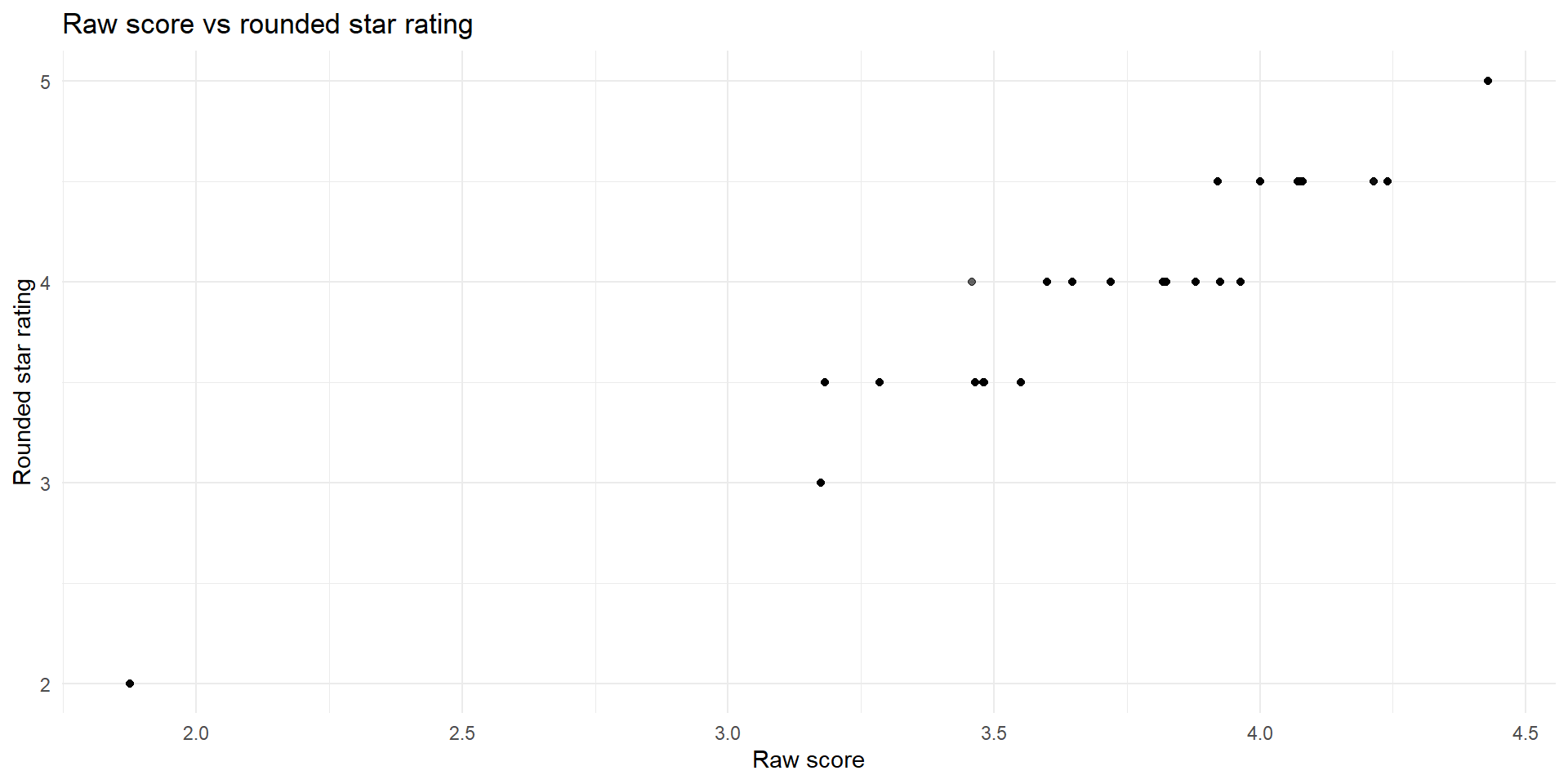
rounding_counts_3_75 <- ga_ma_full %>%
filter(
!is.na(raw_rating), !is.na(partc_score),
partc_score %in% c(3.5, 4.0),
raw_rating >= 3.5, raw_rating <= 4.0,
(raw_rating >= 3.75 & partc_score==4.0) | (raw_rating <= 3.75 & partc_score==3.5)
) %>%
mutate(
`Raw Score` = if_else(raw_rating >= 3.75, "≥ 3.75", "< 3.75"),
`Star` = if_else(partc_score == 4.0, "4.0", "3.5")
) %>%
count(`Raw Score`, `Star`, name = "Plans")
rounding_counts_3_75 %>%
kbl(
format = "html",
caption = "Ratings vs Raw Score"
) %>%
kable_styling(
bootstrap_options = c("striped", "hover", "condensed"),
full_width = FALSE,
position = "center"
)| Raw Score | Star | Plans |
|---|---|---|
| < 3.75 | 3.5 | 35 |
| ≥ 3.75 | 4.0 | 359 |
Potential endogeneity
- The star rating is a measure of quality
- Actual “quality” is not the same as “quality disclosure”
- Quality may be endogenous to enrollment (how?)
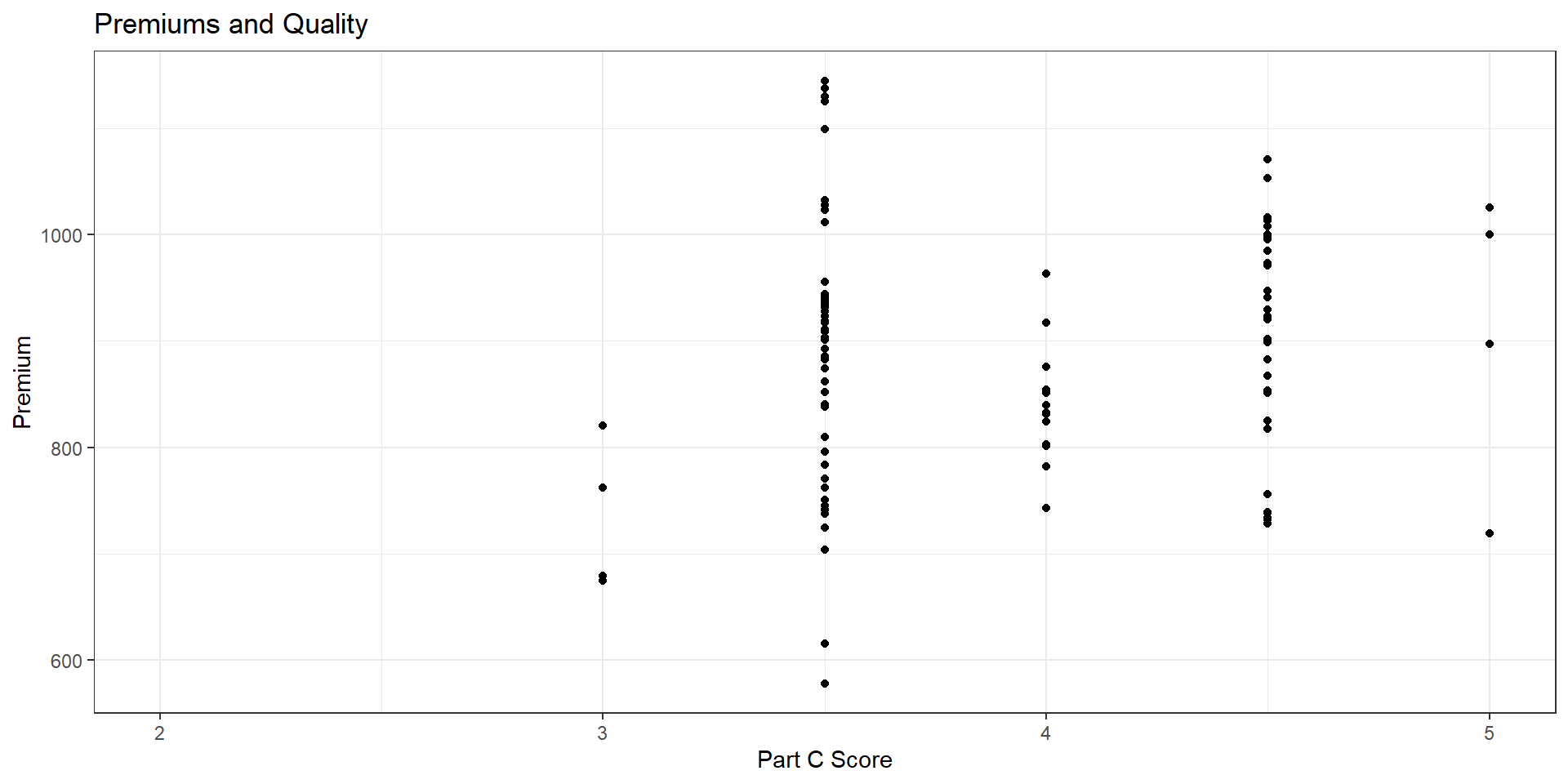
Call:
lm(formula = bid ~ factor(partc_score), data = ga_ma_full)
Residuals:
Min 1Q Median 3Q Max
-261.079 -71.049 9.059 70.648 305.049
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 750.240 6.714 111.739 < 2e-16 ***
factor(partc_score)3.5 89.295 7.392 12.079 < 2e-16 ***
factor(partc_score)4 80.448 7.853 10.244 < 2e-16 ***
factor(partc_score)4.5 181.633 7.284 24.936 < 2e-16 ***
factor(partc_score)5 119.729 17.831 6.715 2.21e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 101.8 on 3272 degrees of freedom
(7 observations deleted due to missingness)
Multiple R-squared: 0.2319, Adjusted R-squared: 0.2309
F-statistic: 246.9 on 4 and 3272 DF, p-value: < 2.2e-16